Configuring HA for PostgreSQL in VMware Data Services Manager v1.3.2
 One the features of Data Services Manager (DSM) that stood out for me was how it could very easily make a standalone database highly available. With just a single click, users can deploy the necessary monitoring VMs (in the case of PostgreSQL, a PG_Monitor) and additional Read Only Replicas. In this post, I will show how to create a highly available database using DSM. I will highlight some of the requirements, and also some of what is taking place under the covers while the HA operation is in progress.
One the features of Data Services Manager (DSM) that stood out for me was how it could very easily make a standalone database highly available. With just a single click, users can deploy the necessary monitoring VMs (in the case of PostgreSQL, a PG_Monitor) and additional Read Only Replicas. In this post, I will show how to create a highly available database using DSM. I will highlight some of the requirements, and also some of what is taking place under the covers while the HA operation is in progress.
Requirements
Let’s begin by outline some of the requirements. The main one is to ensure that your networking is working correctly, and offers the necessary services. In particular, DNS and DHCP need to be working correctly on the “Application” network, as well as a requirement to have DHCP on the “Control Plane” network. The “Application Network” is the network onto which the databases are provisioned and where the database clients make their connections. Hopefully the diagram below helps to visualize the network requirements.

On this blog, we have already discussed the deployment of both the provider and the agent, as well as how to deploy a stand-alone database. In this post will look at a clustered or highly available database deployment. One item to note is that even with a stand-alone database with no replicas, there is a DB FQDN called primary.<fdqn>. While this plays no significant role in stand-alone databases, it is an important feature of highly available databases as we will shortly see.
Create Read Replicas
To enable HA on a stand-alone database, select the database in question in the DSM UI, and navigate to the Cluster Settings tab. In this example, I already have a stand-alone PostgreSQL database called pg-dev-db-1. On the left hand side of the window, you will see that under Cluster Information, the HA Status is currently Unconfigured. To make the database highly available, click on the + Create button highlighted below on the right hand side of the window.

This will launch a wizard to Create a Read Replica. This will start the process of deploying the PG_Monitor VM and the first Read Replica VM. The wizard simply requests the name of the read replica. Other settings can be left at the defaults. In this case, I have given the read replica the imaginative name of pg-replica-1.

The purpose of the PG_Monitor VM is to host a service called pg-auto-failover. pg_auto_failover is an extension and service for PostgreSQL that monitors and manages automated failover of a PostgreSQL cluster. This service requires a monitor to run on. In some respects, the PG_Monitor could be considered as a sort of witness node. PG_Monitor observers the state of the database nodes. It co-ordinates the cluster and initiates fail-overs when appropriate.
If the deployment succeeds, the cluster should now report three VMs – the original database VM, the PG_Monitor VM and the first read replica VM, as shown below. The original stand-alone database also assumes the role of primary in the cluster.

Note that the HA Status has now changed from Unconfigured to Incomplete. It is incomplete becuase a seconds read only replica needs to be deployed to meet the PostgreSQL cluster requirements. A second replica can be created in the exact same way that the first replica was created. If that second replica deploys successfully, then the HA Status should change to Complete.
If an auto-failover occurs in the cluster, and a replica now assumes the role of primary, the DSM control plane will trigger a task called Promote Replica . This will adjust the control plane metadata and update the primary.<fqdn> mapping to the IP address of replica which is now the new primary. The DSM control plane polls the cluster every 5 minutes to see if an auto-failover has occurred.

Success! Note that the Replication Status of the Read Replicas is set to Active, meaning that they are able to successfully communicate with the primary.
VM/Host Groups Integration
Now a question you might ask at this point as a seasoned vSphere Administrator is what happens if the majority of these replica VMs are deployed to the same ESXi host or the same datastore. From a compute perspective, this is handled by the creation of a VM/Host Group which has the rule to keep the VMs separated. This rule is created automatically. Here is the rule from my environment.
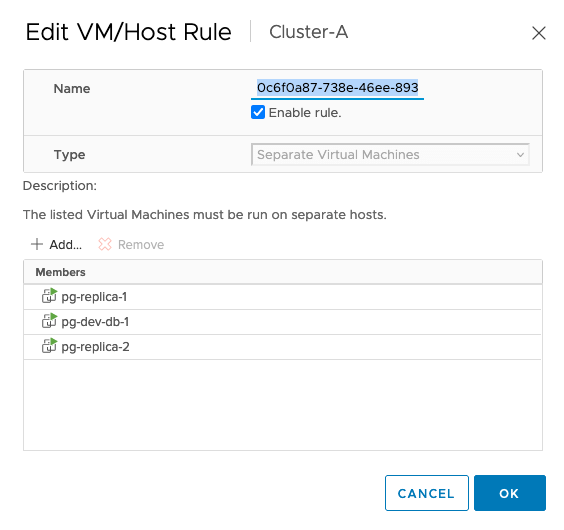 From a storage perspective, you would certainly need to give this some additional consideration to ensure a failure does not impact the datastore on which the VMs reside. In my environment, I am using vSAN with a RAID-1 policy which ensures that a single host failure in my vSphere infrastructure does not lead to data unavailability.
From a storage perspective, you would certainly need to give this some additional consideration to ensure a failure does not impact the datastore on which the VMs reside. In my environment, I am using vSAN with a RAID-1 policy which ensures that a single host failure in my vSphere infrastructure does not lead to data unavailability.
Promote a Replica to Primary
Whilst the PG_Monitor VM will now monitor for failures, and initiate failover events as needed, it is also possible to promote a Read Replica to primary via the DSM UI. Select the Replica that you wish to promote and under the Database Actions drop-down, select Promote Replica.

The status of the Read Replica will temporarily change from Online to Modifying, before assume the role of Primary.
That completes the post. Hope you find it useful, and can see how Data Services Manager can help the management of database fleets running on vSphere infrastructure so much easier for administrators and users alike.
2 Replies to “Configuring HA for PostgreSQL in VMware Data Services Manager v1.3.2”
Comments are closed.