Enabling Pods to pull from external image repositories in vSphere with Kubernetes
![]() Regular readers will know that I have been spending quite a considerable amount of time recently talking about VMware Cloud Foundation (VCF) 4.0 and vSphere with Kubernetes, formerly known as Project Pacific. Over the past month or so, we have seen how to deploy a VCF 4.0 Management Domain. We also looked at how to create a VCF 4.0 VI Workload Domain, at the same time deploying an NSX-T 3.0 Edge Cluster to the Workload Domain which is now automated in VCF 4.0. With this all configured, we then went through the steps of deploying vSphere with Kubernetes onto this newly created Workload Domain, initiated via the new Solutions section in the VCF 4.0 SDDC Manager. We then got a lot deeper into vSphere with Kubernetes, creating namespaces, enabling Harbor Image Registry and deploying our first containerized apps in the Supervisor Cluster. Then we moved onto looking at the steps involved in deploying a Tanzu Kubernetes cluster (formerly known as a Guest cluster) in its own namespace in vSphere with Kubernetes, and deploying containerized apps onto the Tanzu Kubernetes cluster.
Regular readers will know that I have been spending quite a considerable amount of time recently talking about VMware Cloud Foundation (VCF) 4.0 and vSphere with Kubernetes, formerly known as Project Pacific. Over the past month or so, we have seen how to deploy a VCF 4.0 Management Domain. We also looked at how to create a VCF 4.0 VI Workload Domain, at the same time deploying an NSX-T 3.0 Edge Cluster to the Workload Domain which is now automated in VCF 4.0. With this all configured, we then went through the steps of deploying vSphere with Kubernetes onto this newly created Workload Domain, initiated via the new Solutions section in the VCF 4.0 SDDC Manager. We then got a lot deeper into vSphere with Kubernetes, creating namespaces, enabling Harbor Image Registry and deploying our first containerized apps in the Supervisor Cluster. Then we moved onto looking at the steps involved in deploying a Tanzu Kubernetes cluster (formerly known as a Guest cluster) in its own namespace in vSphere with Kubernetes, and deploying containerized apps onto the Tanzu Kubernetes cluster.
In this post I want to revisit an area that I glossed over a little when we deployed the NSX-T 3.0 Edge Cluster, and this was related to choosing the static routes option. Since my deployment is in an environment where I do not have access to the “upstream router”, I was not in a position to peer my NSX-T 3.0 Tier-0 Logical Router with the “upstream router” using BGP, the Border Gateway Protocol. BGP is extremely useful as peered routers share their known routes with each other. Simply put, if a packet arrives in one router, and it doesn’t have a place to directly route it, it can check to see if any of its peered routers knows where to send it and forward it to that router. Without BGP, this becomes a lot more labour intensive.
Now, because I went with static routes for the NSX-T edge cluster deployment, and not BGP, there are a few additional manual steps needed to make the deployment fully functional.
- Add a Tier-0 Logical Router Static Route so that all packets generated on ‘internal’ networks are forwarded. This includes the Load Balancer/Ingress range which is defined during the deployment of vSphere with Kubernetes.
- Add a Tier-0 Logical Router SNAT Rule for the PodVMs created on the Supervisor. This range of IP addresses is already SNAT’ed on the Tier-1 Logical Router, but it requires another SNAT on the Tier-0 to route externally.
- Similarly, add another Tier-0 Logical Router SNAT Rule for the Pods created on the TKG (guest) cluster. This range of IP addresses is already SNAT’ed on the Tier-1 Logical Router created for the TKG cluster, but it also needs another SNAT on the Tier-0 to route externally.
Let’s now go through these steps in more detail.
1. Add Static Route to Tier-0 Logical Router
Without the static route added to the Tier-0 Logical Router, you will not be able to connect to the Ingress range of IP addresses defined during the deployment of vSphere with Kubernetes. The Ingress range is used for Load Balancer IP addresses, so this means that you won’t be able to reach the Supervisor cluster API Server Endpoint. Thus you will be unable to reach the Kubernetes CLI Tools hosted at this location. You will also be unable to reach the TKG clusters API Server Endpoints or the Harbor Image Registry UI, if you choose to deploy either of these.
To add a static route to the Tier-0 Logical Router, login the the NSX-T 3.0 Manager. Ensure “Policy” is select on the top right. Select “Networking”, then “Tier-0 Gateways”. This will list the Tier-0 Gateways aka Logical Routers. Next to the Tier-0 name, there are 3 vertical dots. Click these dots, and this provides a drop-down menu. From the menu, select the “Edit” option. In the Edit view, click on the chevron next to “ROUTING”. Static Routes should currently be 0. Click on the “Set” to add a new static route. In the “Set Static Route” pop-up window, click on “ADD STATIC ROUTE”. Enter a name for the static route, following by a network. In my setup, I set the network to be “0.0.0.0/0” so that everything will be routed. Click on “Set Next Hops”. In the “Set Next Hops” pop-up window, click on “Add Next Hop”. In my case, I added the IP address of the default gateway on the network to which my Edge uplinks were attached. Make sure you click on the “Add” to get the next hop IO address added. Now click on the “ADD” button, then “APPLY” and now “SAVE”. Once saved, my static route configuration now looked something like this (refresh the status until you see Success):
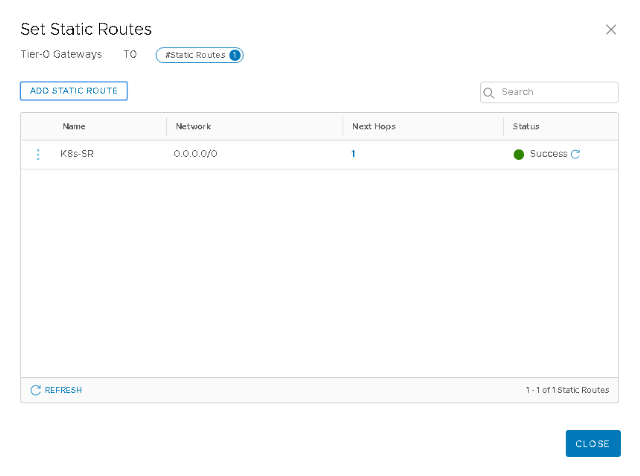
The Static Routes number in the Routing section of the Tier-0 Logical Router should now be set to 1. Click on “Close Editing” on the lower right hand side to finish editing. If everything is working as it should, you should now be able to point a browser to the API Server Endpoint and see the Kubernetes CLI Tools page:

That completes the static route configuration. Let’s now take a look at my networking setup from the new NSX-T 3.0 Network Topology view. This is after I have enabled the Harbor Image Registry, as well as creating a TKG cluster. The group of 3 x VMs that are networked via the domain-c8 Tier-1 Logical Router are the 3 x control plane VMs in my vSphere with Kubernetes Supervisor cluster. The 9 x Pods are the 7 x PodVMs that come from the Harbor Image Registry deployment, as well as two sample PodVMs that I created myself for testing. The group of 4 VMs that are networked via the vnet-domain-c8 Tier-1 Logical Router are the 1 x control plane and 3 x worker nodes of my TKG guest cluster. The other Tier-1 (T1) with no segments connected is built during the NSX-T Edge Cluster deployment from VCF 4.0, but is unused.

With this overview in mind, let’s now look at how to enable the containerized apps/Pods in these different clusters.
2. Add Tier-0 SNAT Rule for Supervisor cluster nodes
If we expand, the Supervisor Control Plane VMs, we see the following network topology. We see that it is connected to a Tier-1 Logical Router through the 10.244.0.97/28 network segment. If you click on one of the control plane VMs, it highlights the network path in blue, as shown below.

In the NSX-T 3.0 Manager, if we navigate to Network Services > NAT and select the domain-c8 Tier-1 Logical Router, we can see the SNAT rules that have been put in place when vSphere for Kubernetes is deployed. We can see that the 10.244.0.97/28 range is translated to an IP address defined in the Egress range provided at deployment time. In my case, the Egress range was defined as 30.0.0.0/24 during vSphere with Kubernetes deployment. Here we see the translation address mapped to 30.0.0.5 in this case.

However this is a SNAT between the Tier-1 and Tier-0. We do not have a SNAT to allow that 30.0.0.5 address to get out externally (or at least, get replies back). This is how the issue manifests itself when we attempt to create a PodVM which tries to pull an external image in a namespace in vSphere with Kubernetes. The following events are taken from the kubectl describe pod of a failed PodVM deployment, which was trying to pull a busybox image from an external google repository (scroll right for the messages). We can see that connection timed out.
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled <unknown> default-scheduler Successfully assigned podvm-ns/ch-busybox to esxi-dell-n.rainpole.com Normal Image <invalid> image-controller Image busybox-91fc8f6fc85b4a0bfe94da01c9913d8e9bcdfb96-v0 bound successfully Normal SuccessfulRealizeNSXResource <invalid> (x3 over <invalid>) nsx-container-ncp, 421df2f065306960d445646b70afb7e8 Successfully realized NSX resource for Pod Normal Pulling <invalid> kubelet, esxi-dell-n.rainpole.com Waiting for Image podvm-ns/busybox-91fc8f6fc85b4a0bfe94da01c9913d8e9bcdfb96-v0 Warning Failed <invalid> kubelet, esxi-dell-n.rainpole.com failed to get images: Image podvm-ns/busybox-91fc8f6fc85b4a0bfe94da01c9913d8e9bcdfb96-v0 has failed. Error: Failed to resolve on node esxi-dell-n.rainpole.com. Reason: Http request failed. Code 400: ErrorType(2) failed to do request: Head https://k8s.gcr.io/v2/busybox/manifests/latest: dial tcp 74.125.133.82:443: connect: connection timed out
The 30.0.0.5 IP addresses cannot reach my external network, thus it cannot reach external image repositories. I need another SNAT rule, but this time to translate the 30.0.0.5 IP address to an IP address that resides on my external network and can be routable to the outside world. In my case, I chose one of the IP addresses that my NSX-T Edge is using as an uplink (10.27.51.145).
Staying in the NAT section of the NSX-T Manager, change the gateway to the Tier-0 Logical Router. Next, click on “Add NAT Rule”. Provide a name for the rule, leave the action as Reflexive (only option when NSX-T edge Cluster configuration is Active/Active), and enter the Source IP address of 30.0.0.5. In the Translated field, add an address on the external network. In my case, I picked one of my NSX-T Edge Uplink IP addresses of 10.27.51.145. Everything else can be left at the default. Click Save. The rule should look something like this:

After the Tier-0 SNAT rule is in place for the Supervisor, you can retry the deployment of the busybox PodVM. This should now succeed (scroll right for the messages).
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled <unknown> default-scheduler Successfully assigned podvm-ns/ch-busybox to esxi-dell-n.rainpole.com Normal Image <invalid> image-controller Image busybox-91fc8f6fc85b4a0bfe94da01c9913d8e9bcdfb96-v0 bound successfully Normal SuccessfulRealizeNSXResource <invalid> (x3 over <invalid>) nsx-container-ncp, 421df2f065306960d445646b70afb7e8 Successfully realized NSX resource for Pod Normal Pulling <invalid> kubelet, esxi-dell-n.rainpole.com Waiting for Image podvm-ns/busybox-91fc8f6fc85b4a0bfe94da01c9913d8e9bcdfb96-v0 Normal Pulled <invalid> kubelet, esxi-dell-n.rainpole.com Image podvm-ns/busybox-91fc8f6fc85b4a0bfe94da01c9913d8e9bcdfb96-v0 is ready
Now that the Supervisor cluster is able to successfully pull images from external image repositories, let’s turn our attention to the TKG clusters and enable it to also pull images from an external repository.
3. Add Tier-0 SNAT Rule for TKG cluster nodes
Just like we did for the Supervisor control plane, let’s examine the network topology for the Tanzu Kubernetes cluster first. We can see that it has its own Tier-1 Logical Router (vnet-domain-c8) which is in turn connected to the same Tier-0 Logical Router as the Supervisor control plane VMs.

Before I do anything with SNAT in NSX-T 3.0, let’s look at what happens if I attempt to create a containerized application (Pod) using an image from an external repository in this TKG cluster (scroll right for the messages). Again, we see another timeout message, similar to what we saw on the Supervisor when attempting to pull an image from an external repository.
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled <unknown> default-scheduler Successfully assigned default/ch-busybox to ch-tkg-cluster01-workers-lwnf7-7988497879-h6cwg Normal BackOff <invalid> kubelet, ch-tkg-cluster01-workers-lwnf7-7988497879-h6cwg Back-off pulling image "k8s.gcr.io/busybox" Warning Failed <invalid> kubelet, ch-tkg-cluster01-workers-lwnf7-7988497879-h6cwg Error: ImagePullBackOff Normal Pulling <invalid> (x2 over <invalid>) kubelet, ch-tkg-cluster01-workers-lwnf7-7988497879-h6cwg Pulling image "k8s.gcr.io/busybox" Warning Failed <invalid> (x2 over <invalid>) kubelet, ch-tkg-cluster01-workers-lwnf7-7988497879-h6cwg Failed to pull image "k8s.gcr.io/busybox": rpc error: code = Unknown desc = Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) Warning Failed <invalid> (x2 over <invalid>) kubelet, ch-tkg-cluster01-workers-lwnf7-7988497879-h6cwg Error: ErrImagePull
We are in a similar situation to before. We must add another SNAT rule to the Tier-0 Logical Router which will allow the Pods in the TKG cluster communicate to the external network. They have already been SNAT’ed on the Tier-1 Logical Router, as we can see here, when the TKG cluster was created. The translated IP address for the addresses used by the TKG nodes is 30.0.0.16.

As before, navigate back to the Tier-0 Logical Router, and add a new SNAT rule, just like we did before. However, this time, I will use the IP address of the other NSX-T Edge Uplink IP address (10.27.51.147) for the translation.

And now if I create a new Pod in the TKG cluster, it succeeds in pulling the image from an external repository.
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled <unknown> default-scheduler Successfully assigned default/ch-busybox to ch-tkg-cluster01-workers-lwnf7-7988497879-xzd8h Normal Pulling <invalid> kubelet, ch-tkg-cluster01-workers-lwnf7-7988497879-xzd8h Pulling image "k8s.gcr.io/busybox" Normal Pulled <invalid> kubelet, ch-tkg-cluster01-workers-lwnf7-7988497879-xzd8h Successfully pulled image "k8s.gcr.io/busybox" Normal Created <invalid> kubelet, ch-tkg-cluster01-workers-lwnf7-7988497879-xzd8h Created container busybox Normal Started <invalid> kubelet, ch-tkg-cluster01-workers-lwnf7-7988497879-xzd8h Started container busybox
At this point, I am able to successfully deploy images that reside external to the cluster to containers in my TKG cluster. If you are in an environment where you do not have access to the upstream router, or you are running a simple lab where you don’t want to use BGP, then the steps outlined should get you up and running with vSphere with Kubernetes.
4. Other Image Pull Issues – DNS
I wanted to close with another issue which may prevent you from being able to successfully pull images from external repositories, and this is when DNS is not working correctly. Note that your Pods will now need to resolve hostnames such as k8s.gcr.io and so on. Therefore it will need to access your DNS server, which you provided during the vSphere with Kubernetes deployment. Since these requests will be appearing on the Egress IP address range (in my case 30.0.0.x), I needed to add a static route to my DNS server so that it knows how to respond to requests from this network. Before I added this static route, my image pulls were failing as follows (scroll right for the messages):
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled <unknown> default-scheduler Successfully assigned default/ch-busybox to ch-tkg-cluster01-workers-kjbtn-54b75dd4d7-mllkf Normal Pulling <invalid> kubelet, ch-tkg-cluster01-workers-kjbtn-54b75dd4d7-mllkf Pulling image "k8s.gcr.io/busybox" Warning Failed <invalid> kubelet, ch-tkg-cluster01-workers-kjbtn-54b75dd4d7-mllkf Failed to pull image "k8s.gcr.io/busybox": rpc error: code = Unknown desc = Error response from daemon: Get https://k8s.gcr.io/v2/: dial tcp: lookup k8s.gcr.io on 127.0.0.53:53: read udp 127.0.0.1:54821->127.0.0.53:53:i/o timeout Warning Failed <invalid> kubelet, ch-tkg-cluster01-workers-kjbtn-54b75dd4d7-mllkf Error: ErrImagePull
Note that the above is a lookup failure, rather than an inability to reach the external repository. This issue has also caught me out, so be sure to carefully read the reason for the failure in the kubectl describe pod output before troubleshooting.
Final word of thanks – kudos again to Ianislav Trendafilov from our Sofia office who is always available to answer my NSX-T related questions.