Enabling vSphere with Tanzu using HA-Proxy
![]() In earlier posts, we look at the differences between the original “VCF with Tanzu” offering and the new vSphere with Tanzu offering from VMware. One of the major differences is the use of HA-Proxy to provide a load balancing service, and the deployment steps of the HA-Proxy we covered in detail in a follow-up post. In this post, we are now ready to deploy vSphere with Tanzu, also known as enabling Workload Management.
In earlier posts, we look at the differences between the original “VCF with Tanzu” offering and the new vSphere with Tanzu offering from VMware. One of the major differences is the use of HA-Proxy to provide a load balancing service, and the deployment steps of the HA-Proxy we covered in detail in a follow-up post. In this post, we are now ready to deploy vSphere with Tanzu, also known as enabling Workload Management.
Prerequisites Revisited
The prerequisites were covered in detail in the “Getting started” post, and you won’t have been able to successfully deploy the HA-Proxy without following them. There are two prerequisites which are required when enabling workload management, so let’s revisit those. First, make sure that you have the appropriate storage policy for the Supervisor control plane VMs created, and, second, ensure that a Content Library with the TKG images subscription URL in place. Navigate to Workload Management in the vSphere Client UI and click on Get Started, as shown below:

The first requirement is to select a networking stack. Whilst you can continue to use NSX-T with vSphere with Tanzu, we are going to go with the vCenter Server Network, meaning we will be using a vSphere Distributed Switch (VDS). Remember however, as pointed out in previous posts, use of the vCenter Server Network (VDS + HA-Proxy) precludes you from using the PodVM service.

Next, select the cluster on which you wish to install vSphere with Tanzu. I have only one cluster in my environment, so that is the only option available.

Now you need to select a control plane size. I don’t really have any advice to offer here on how to size the control plane at this point. My guess is that this will come in official documentation. I chose small, as I don’t plan to do much other than deploy a simple TKG cluster or two. Resource details are shown against each size.

Next, select a storage policy for the control plane disks. Since I use vSAN for the underlying datastore, I am simply selecting the vSAN default policy from the drop-down list of policies:

Next up is to step to configure the Load Balancer on the Frontend network. This is where we tell vSphere with Tanzu about HA-Proxy. Note that the Name should be very simple (don’t use any special characters). Type is obviously HA Proxy. The Data path API address is the IP address of the HA Proxy on the management network plus the Dataplane API management port (default 5556) so in my setup this was 10.27.51.134:5556. User name and password are what was provided when we provisioned the HA Proxy previously. The IP address Ranges for Virtual Servers is the range of Load Balancer IP addresses we provided when configuring the HA-Proxy – 192.50.0.176/29 – which provides 8 load balancer IP addresses ranging from 192.50.0.176-192.50.0.183. Note you must provide the range and not a CIDR in this case. Lastly we need the Server Certificate Authority. This can be found by SSH’ing as root to the HA-Proxy appliance, and copying the contents of the /etc/haproxy/ca.crt file to here. Note however that I have inadvertently used the /etc/haproxy/server.crt as well, and this has seemed to have worked as well. However, I’ve been informed that it is preferable to use the ca.crt, since that is the CA that was used to sign the actual certificate (server.crt) that the DataPlane API endpoint on HAProxy will serve.

Now we setup the Management network. These are the IP addresses that will be used by the Supervisor Control Plane VMs. You will need to provide a starting IP address, but you should provide a minimum of 4. A 3 node Supervisor control plane will requires at least this many. However, it would be useful to make sure there are even more IP addresses available in the range for the purpose of patching, upgrades, etc. Official documentation should provide guidance on this. The rest of the fields here, such as NTP, DNS and Gateway, are self-explanatory.

The final network that needs to be configured is the Workload network. This network is used by both the Supervisor control plane nodes and the TKG “guest” cluster nodes. You will notice that the Supervisor control plane nodes get a second network interface plumbed up, connecting them to the portgroup of the workload network. On completion of the setup, the Supervisor control plane VMs should have network interfaces on both the management network and the workload network.
The IP address range for Services can be left at the default, but you will need to click the ADD button to add the workload network. Select the portgroup for the workload network, provide gateway, subnet mask and a range of IP addresses that can be used for the network. I provided a range of 16 free IP addresses.

There is the option to create additional workload networks, but I am only creating one.Once saved, the workload network should look something like this.

Next, select the Content Library that holds the TKG images. This should have already been created, as it was called out in the prerequisites. In my setup, I called the Content Library Kubernetes. This needs to be synchronized to the TKG image subscription URL – https://wp-content.vmware.com/v2/latest/lib.json. This Content Library will automatically be available in the vSphere with Tanzu Namespaces that we will create later, once vSphere with Tanzu is up and running. If you are setting up vSphere with Tanzu in an air-gapped/dark site, there is a documented procedure on how to setup the Content Library in an Air-Gapped environment.

Finally everything is in place to start enabling workload management / vSphere with Tanzu. Click the Finish button.

You should now observe that the cluster starts to configure:

A lot of configuration steps now start to take place, such as deploying the Supervisor cluster control plane VMs, and plumbing them up onto both the management network and the workload network. The control plane API server should also get a load balancer IP address allocated from the configured range of IP addresses on the frontend network. If you want to trace the log output for a deployment, SSH onto the vCenter server, navigate to /var/log/vmware/wcp and run a tail -f wcpsvc.log. Note that this generates a lot of logging, but might be useful in identifying the root cause of a failure. If the deployment completes successfully, you should see the Control Plane IP address configured with one of the Load Balancer / frontend IP address range. In fact, in my case, it is the first IP address in that range – 192.50.0.176.

And now you should be able to connect to the Control Plane IP address and see the Kubernetes CLI Tools landing page.
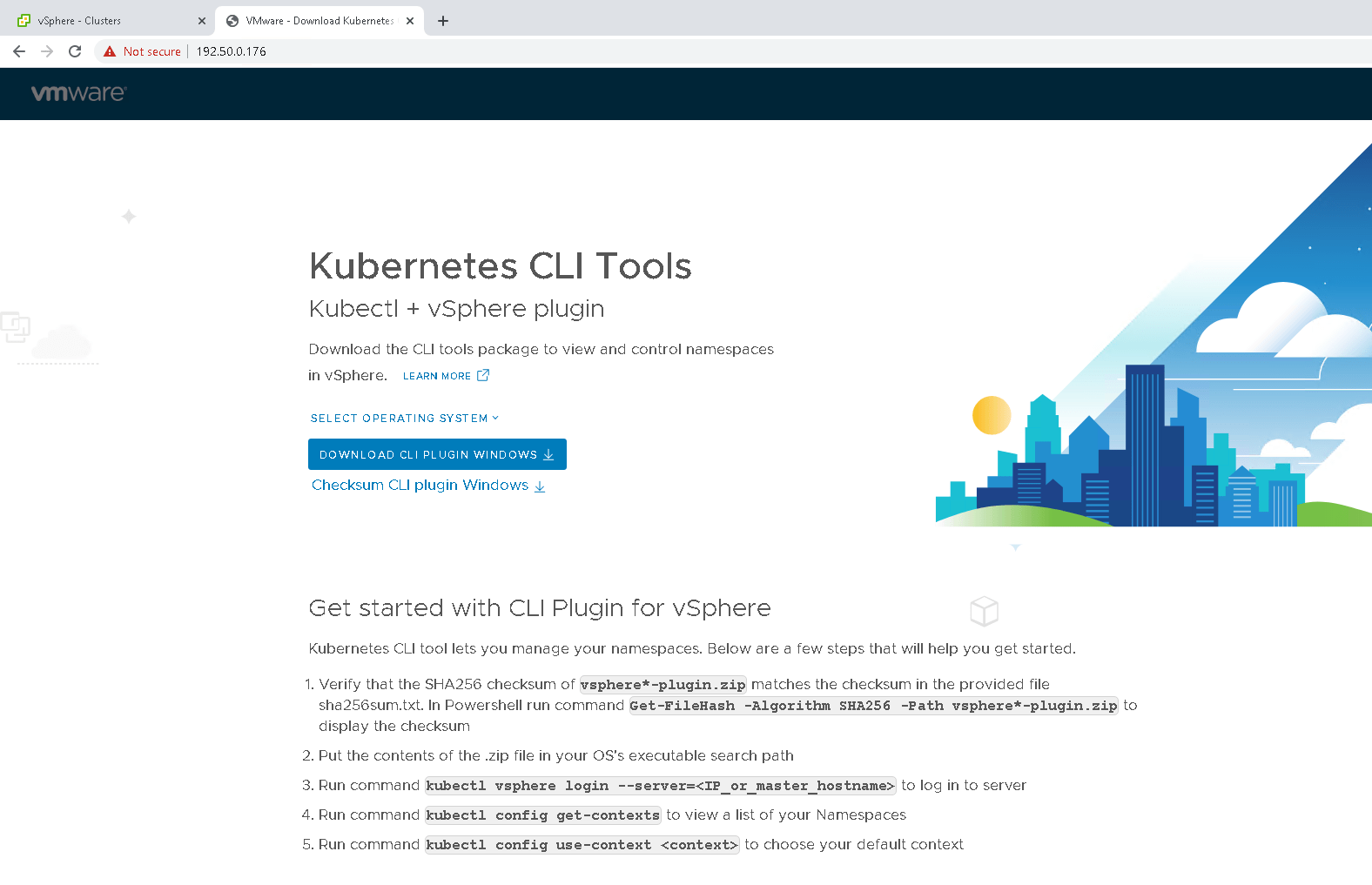
Success! We have deployed vSphere with Tanzu with a HA-Proxy, which has been able to provide a load balancer IP address to our Supervisor cluster control plane. From a networking perspective, this is how my setup looks at the moment, now that the Supervisor control plane (virtual machines SV1-3) has been deployed.

At this point, we have looked at the prerequisites for getting started with vSphere with Tanzu. We have also looked at the deployment of HA-Proxy. In this post, we have covered how to deploy/configure Workload Management/vSphere with Tanzu. In my final post, I will cover the remaining tasks which will include how to create a Namespace, how to login to vSphere with Tanzu and how to deploy a TKG cluster. Stay tuned!
Hey Cormac,
Hope you are doing great,
I’ve been following this amazing blog,
Somehow I am not able to open the Control Plane Node IP Address web console,
It tries to bring up the webconsole but it times out,
The ip is reachable and the supervisors with the IP from the same range show their web console fine.
Don’t know if you have an idea about it
Do you mean the landing page for the K8s tools Jorlius, or do you mean something else? I’m not 100% sure what you mean by web console.
Cormac,
Regarding image “2.-select-a-network-stack.png”, if you already had NSX-T implemented in vCenter, would NSX-T be an available option here? If not, what makes it be available as an option?
Additional question, does the “Enterprise Plus with Kubernetes” license or the “add-on for Kubernetes” license enable both options (NSX-T and vCenter Server Network) assuming you have additional licenses for NSX-T? Just checking my understanding that both NSX-T and vCenter Server Network are both options included in vSphere Tanzu.
Hi Richard,
Yes – if you have NSX-T, you can absolutely use that for the underlying network platform for vSphere with Tanzu. You do not need to deploy a HA-Proxy in that case, and you also can leverage the PodVMs feature and Harbor Image Registry.
I’m not 100% clear on the licensing, but I believe there is a new license with vSphere 7.0U1 to allow you to enable vSphere with Tanzu. This should be in the docs, or if not, please reach out to your closest VMware rep for further details.
Hello Cormac,
Thanks a lot for your blog post ! Quick question before starting the deployment. If I choose vCenter Server Network, will I be able to go back to NSX-T ? At which level do you enable the vCenter Server Network ? vSphere Cluster, vCenter ? Or even Linked vCenters ?
Thanks
Hi Tristan – VDS is enabled at the vSphere cluster level, same as vSphere with Tanzu. I don’t believe you can move between the HA-Proxy and NSX-T network providers though (as per my other response). I think it is one or the other.
Hello,
thanks for this tutorial. I test this in a nested lab and i end up with an error when enabling the workload management.
download remote files: HTTP communication could not be completed with status 404.
My ha proxy and my supervisor are on the same network as my esxi and vcenter.
I connect to the ha proxy and everything seems fine about connection.
What i saw it’s that i have this error but it end up by deploying the supervisor without IP and after a while it destroy the supervisor and deploy another one and that never end.
Did you see this error?
What are those remote file it try to download
regards
Hi Anthony – no, I did not see this error, but I know the networking is a bit tricky with the HA-Proxy.
The “HTTP communication could not be completed with status 404” are transient and can be ignored.
I think there must be another reason for the Supervisors to be deployed without IP addresses. I’m not sure what that would be, but I would speak to GSS and see if they can help.
Hi Cormac, Anthony. I had the same issue in my nested homelab. I found a way to bypass this error by disabling the firewall completely on the nested host in a Tanzu cluster:
root # esxcli network firewall set –enabled false
Don’t ask me why it works though!
Always good to have people share their experiences – thanks for this Paul.
I can confirm that this helps. I assume that this is a bug in the setup process – the ports are not opened, yet.
Hi! First Thanks for the excellent tutorials! I have the same Problem, 404 and then never ends up… (also nested), did you find the reason? Thank a lot
404 errors in the task bar can be ignored Paul. What happens with the configuring step? Does it just seem to go on forever? Do the SV VMs get deployed, deleted and then redeployed?
It is hard for me to answer questions about what happens in a nested setup as I have not tested it I am afraid.
Hi Thanks for your answer! Now it works. Nested is not the problem. The problem might come from different networks. My first test (that failed) had three different network, and important the MGMT Network was a different Layer 3 network than the ESX hosts. I than did the same Lab as you (ESX and MGM same network, Frontend and Workload on same (different) VLAN and now it works! Have to do further test to understand exactly why it did not work before … The important question would be: Can the MGMT network (for tanzu) be on a differnet network (routable) than the ESX Hosts or should/must it be the same? Thank you agin for the very good tutorials!
In my setup, my management network is also on a different network (VLAN) to my workload and frontend. However, I was able to successfully deploy when the management and worklaod/frontend were routable to each other, and again, when they were not.
However in all cases, the management network was the same one shared with vCenter server and the ESXi hosts management interface.
Hi Cormac, i have tried to following your procedure to deploy vsphere with tanzu in my hole lab. During cluster selection step i have found my cluster in incompatible status with next incompatibility reason: Cluster domain-c2001 is a personality-manager managed cluster. It currently does not support vSphere namespaces.
Any ideas what can cause this issue? I have tried to find anything related in knowledge base with no success.
What does it mean – personality-manager managed cluster?
Thanks an advance
I believe personality manager may be vSphere Life Cycle Manager, but I am not sure why there is an incompatibility reason.
Are you using vSphere 7.0U1?
Hi Cormac, thank you for fast answer. Right – i am using Version: 7.0.1 Build:16858589.
I have checked here – https://docs.vmware.com/en/VMware-vSphere/7.0/com.vmware.vsphere-lifecycle-manager.doc/GUID-C249B35E-7689-4D82-8ABA-0B04FBA6F127.html.
You can enable vSphere with Tanzu on a cluster that you manage with a single vSphere Lifecycle Manager image
Seems that’s shouldn’t be constraint for vSphere with Tanzu enablement
Hi Alexander
i had the same error as you and i have single image config on the cluster, i created another cluster without single image setup for the cluster, that cluster was compatible so i think the single image config is blocking the Tanzu setup for that cluster.
BR
Ingvar
good to know – thanks for sharing Ingvar
Hello Cormac, I tried this in my nested lab and it is failing with an error while enabling workload mgmt.
Supervisor control plane failed: No connectivity to API Master: connectivity Get https://10.155.124.67:6443/healthz?timeout=5s: dial tcp 10.155.124.67:6443: connect: connection refused, config status ERROR.
From VC the connection is refused to API master
curl -v telnet://10.155.124.67:6443
* Rebuilt URL to: telnet://10.155.124.67:6443/
* Trying 10.155.124.67…
* TCP_NODELAY set
* connect to 10.155.124.67 port 6443 failed: Connection refused
* Failed to connect to 10.155.124.67 port 6443: Connection refused
* Closing connection 0
curl: (7) Failed to connect to 10.155.124.67 port 6443: Connection refused
And one more things I noticed is the Server Certificate Authority file, as per https://docs.vmware.com/en/VMware-vSphere/7.0/vmware-vsphere-with-tanzu/GUID-8D7D292B-43E9-4CB8-9E20-E4039B80BF9B.html it is advised to use /etc/haproxy/ca.crt. Should we use server.crt or ca.crt for this ?
I really don’t know what the issue could be Sushil, but thanks for the note about the ca.crt. It seems both will work, but the advice should be to use the ca.crt, which is used to sign the server.crt.
I’ve updated the post to reflect the official documentation – thanks for catching.
Hi Cormac, getting an error in my nested lab Supervisor control plane failed: No connectivity to API Master: connectivity Get https://10.155.124.67:6443/healthz?timeout=5s while enabling workload mgmt. Do you any suggestions for this?
Is there a route from the workload domain to the load balancer/frontend network? Firewall issues? Promiscuous mode not set? These are just some guesses. It is impossible for me to troubleshoot issues in the comments of this post.
Hi Comac. Any hint on this issue (Thanks in advance) ?
Tanzu + HAProxy are deployed without problem, I can see the namespace tool page on port 6443 and kubectl work fine. But when deploying the guest-cluster using the same cluster.yml than you, it only deploy one control-plane VM then the describe tanzukubernetesclusters show me this status:
Status:
Addons:
Authsvc:
Last Error Message: unable to create or update authsvc: Get https://10.128.4.36:6443/api/v1/namespaces/vmware-system-auth?timeout=10s: context deadline exceeded (Client.Timeout exceeded while awaiting headers)
Name:
Status: error
Cloudprovider:
Name: vmware-guest-cluster
Status: applied
Version: 0.1-77-g5875817
Cni:
Last Error Message: failed to create or update secret in guest cluster: Antrea Certificate for cluster clusters-ns/tkg-cluster-01-antrea is not in healthy statu
s: {Conditions:[] LastFailureTime: NotAfter:}
Name:
Status: error
Csi:
Last Error Message: Post https://10.128.4.36:6443/apis/storage.k8s.io/v1beta1/csidrivers?timeout=10s: net/http: request canceled (Client.Timeout exceeded while
awaiting headers)
Name:
Status: error
Dns:
Last Error Message: unable to reconcile kubeadm ConfigMap’s CoreDNS info: unable to retrieve kubeadm Configmap from the guest cluster: configmaps “kubeadm-confi
g” not found
Name:
Status: error
Proxy:
Last Error Message: unable to retrieve kube-proxy daemonset from the guest cluster: daemonsets.apps “kube-proxy” not found
Name:
Status: error
Psp:
Name: defaultpsp
Status: applied
Version: v1.17.7+vmware.1-tkg.1.154236c
I think I answered a similar query already – I think I observed this behaviour when the FrontEnd network and the Workload network were not routable to each other. Can you check if that is the case with you?
Hi Cormac –
I have a cluster which is in a perpetual state of either “configuring” or “error”. It completed the control plane deployment and I was even able to deploy a cluster under a new namespace without issue. The second control plane VM is the problem and it comes back as NotReady, while the other 2 are fine. Can I force a redeployment of just that one VM by say deleting it or doing something with kubeadm? There are generally 3 errors which repeat, though I imagine only the first one matters:
System error occurred on Master node with identifier 42228844b648f51c40f23db39988d315. Details: Script [‘/usr/bin/kubectl’, ‘–kubeconfig’, ‘/etc/kubernetes/admin.conf’, ‘get’, ‘node’, ‘42228844b648f51c40f23db39988d315’, ‘-o’, ‘jsonpath=\'{.status.addresses[?(@.type == “InternalIP”)].address}\”] failed: Command ‘[‘/usr/bin/kubectl’, ‘–kubeconfig’, ‘/etc/kubernetes/admin.conf’, ‘get’, ‘node’, ‘42228844b648f51c40f23db39988d315’, ‘-o’, ‘jsonpath=\'{.status.addresses[?(@.type == “InternalIP”)].address}\”]’ returned non-zero exit status 1..
VMware is in a perpetual cycle where it reconfigures every x minutes but I can’t see it will ever work without manual intervention. Any recommendations? Thanks.
You could try to reset the WCP service on the vCenter Server Drew – (vmon-cli -r wcp) – that’s about the only step I am aware of. Are you sure there is no IP address clash for the range of IP addresses that are used by the second deployment?
Thanks Cormac I will try. It’s an incredibly strange thing. The two IP addresses that the control plane reports resolve to Kubernetes CLI Tools without issue, just like the other control planes. I have allocated 7 load balancer IPs. You did more, but is 7 too little perhaps (I am very limited in IPs)? What I see is that the first plane took 3 of those IPs, then each of the other planes took 2. One of those planes with 2 is perfectly fine so I did not suspect that to be a problem. I just figured VMware takes all of them and allocates across the 3 planes. And again, the failure of this one plane does not seem to impact my ability to use the functionality which is nice.
Hi Drew – yes, that is expected. You should be able to access the tools from any SV, and indeed access the control plane API server. However it is the Load Balancer IP address which provides that seamless availability in case one SV fails, so really you should try to get that working if you can.
Now from your description, you might be mixing Load Balancer/Virtual IP ranges with the Workload IP range.
When the SVs deploy, they get an interface and IP address on the Management network and an interface and IP address on the Workload network from the “Workload IP address range”. Once these are up, a single IP address from the Load Balancer IP address range is then assigned.
7 IP addresses in a “Load Balancer range” should be fine for small tests, but the “Workload range” will require 3 addresses for the SVs, and then any number of IP addresses depending on how big and how many TKG guest clusters you build, since each node deployed in the TKG cluster requires an IP address in the “Workload range” and a single Load Balancer IP address from the “Load Balancer range”.
Good luck.
Hi Cormac, great post. We followed you post strictly – The Cluster is running, but the Loadbalancer isn’t working. We can’t open the Control Plane Website :443 or 6443.
C:\VMWare\k8\bin>kubectl-vsphere.exe login –insecure-skip-tls-verify –vsphere-username administrator@vsphere.local –server=https://10.80.134.176
time=”2020-11-12T10:38:23+01:00″ level=error msg=”Error occurred during HTTP request: Get https://10.80.134.176/wcp/loginbanner: dial tcp 10.80.134.176:443: connectex: A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond.”
There was an error when trying to connect to the server.\n
Please check the server URL and try again.time=”2020-11-12T10:38:23+01:00″ level=fatal msg=”Error while connecting to host 10.80.134.176: Get https://10.80.134.176/wcp/loginbanner: dial tcp 10.80.134.176:443: connectex: A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond..”
All I can suggest is that you revisit the LB configuration Alexander.
1. Ensure that there are no ranges overlapping.
2. Ensure that the LB IP addresses are pingable on the HA Proxy before proceeding with the deployment of vSphere with Tanzu
3. Make sure there is no other IP address on that range
4. Make sure all subnet masks and CIDRs match across HA-Proxy and vSphere with Tanzu (use a CIDR calculator) – also make sure that ranges start and stop on CIDR boundaries
5. Make sure that there is no service such as DHCP providing IP addresses on the same range
We are trying to simplify things, add guardrails and pre-checks to avoid these issues going forward. But, yes, at present, it is challenging to get everything right first time to deploy this.
Hi Cormac,
I always hang up enabling workload management: failed to configure Master node virtual machine
2020-11-03T02:01:10.713Z debug wcp [opID=5fa0aa0b-domain-c9] VM VirtualMachine:vm-48 current Annotation: This Virtual Machine is a VMware agent implementing support for vSphere Workloads. Its lifecycle operations are managed by VMware vCenter Server.
EAM Agency: vmware-vsc-apiserver-72s6r4
2020-11-03T02:01:10.713Z debug wcp [opID=5fa0aa0b-domain-c9] Found corresponding EAM Agency name for VM VirtualMachine:vm-48: vmware-vsc-apiserver-72s6r4
2020-11-03T02:01:10.713Z debug wcp [opID=5fa0aa0b-domain-c9] VM VirtualMachine:vm-48 Annotation already contains EAM Agency Name, no need to reconfigure.
2020-11-03T02:01:10.752Z debug wcp informer.processLoop() lister.List() returned
2020-11-03T02:01:10.83Z debug wcp [opID=5fa0aa0b-domain-c9] Failed to delete file from /dev/shm/secret.tmp: ServerFaultCode: File /dev/shm/secret.tmp was not found
2020-11-03T02:01:11.091Z info wcp [opID=5fa0aa0b-domain-c9] Certificate already exists on node.
2020-11-03T02:01:11.183Z error wcp [opID=5fa0aa0b-domain-c9] Failed to install API server. Err: Configure operation for the Master node VM with identifier vm-48 failed.
2020-11-03T02:01:11.183Z error wcp [opID=5fa0aa0b-domain-c9] Error configuring API server on cluster domain-c9 Configure operation for the Master node VM with identifier vm-48 failed.
Any suggestions?
Hi Lennon,
I’m afraid I’m not in a position to help you to troubleshoot this. I’d urge you to open an SR with our support org to find out what the issue is.
Cormac
Thanks Cormac!
Hi
I followed steps, have problems deploying first cluster yaml. It deploys first VM (ControlPlane) and than got stuck when it should deploy worker VMs…
It keeps complaining about IP not set but I can see IP on VM level. Not even pingable, don’t know if it should be or not?
HAproxy.cfg got configuration for backend/frontend.
Any ideas?
Thank you
unexpected error while reconciling control plane endpoint for simple-cluster: failed to reconcile loadbalanced endpoint for WCPCluster tanzu-namespace-01/simple-cluster: failed to get control plane endpoint for Cluster tanzu-namespace-01/simple-cluster: VirtualMachineService LB does not yet have VIP assigned: VirtualMachineService LoadBalancer does not have any Ingresses
vm does not have an IP address: vmware-system-capw-controller-manager/WCPMachine/infrastructure.cluster.vmware.com/v1alpha3/tanzu-namespace-01/simple-cluster/simple-cluster-control-plane-hwfmv-2c79j
It sounds like a subnet mask on the CIDR range is not correct if this is what you are seeing.
I have created 2 new VLANs for Workload and Frontend, both /24 so there “should” not be any overlapping issues with CIDR etc…
Will check again and let you know.
Thank you
Hi Cormac
Deployed everything from scratch few times, different subnets, CIDR with calculator,…Still the same error – only Control Plane deploys with simple yaml and then stuck…
I am using “old” vcenter and new nested ESXi with VSAN. Could it be something with vCenter? Some time back had been using it for NSX-T testing, out of ideas and very eager to get this k8s up and running…
1. kubectl get events -w
unexpected error while reconciling control plane endpoint for simple: failed to reconcile loadbalanced endpoint for WCPCluster tanzu-ns-01/simple: failed to get control plane endpoint for Cluster tanzu-ns-01/simple: VirtualMachineService LB does not yet have VIP assigned: VirtualMachineService LoadBalancer does not have any Ingresses
Created MachineSet “simple-workers-kszj2-d4c6b6f49”
Created machine “simple-workers-kszj2-d4c6b6f49-m6sg9”
Created machine “simple-workers-kszj2-d4c6b6f49-795l5”
Created machine “simple-workers-kszj2-d4c6b6f49-5z5zg”
vm is not yet created: vmware-system-capw-controller-manager/WCPMachine/infrastructure.cluster.vmware.com/v1alpha3/tanzu-ns-01/simple/simple-control-plane-hfrm7-7twzk
vm does not have an IP address: vmware-system-capw-controller-manager/WCPMachine/infrastructure.cluster.vmware.com/v1alpha3/tanzu-ns-01/simple/simple-control-plane-hfrm7-7twzk
Success
2. kubectl describe tkg
Cluster API Status:
API Endpoints:
Host: 172.16.97.194
Port: 6443
Phase: Provisioned
Node Status:
simple-control-plane-rb7r6: pending
simple-workers-kszj2-d4c6b6f49-5z5zg: pending
simple-workers-kszj2-d4c6b6f49-795l5: pending
simple-workers-kszj2-d4c6b6f49-m6sg9: pending
Phase: creating
Vm Status:
simple-control-plane-rb7r6: ready
simple-workers-kszj2-d4c6b6f49-5z5zg: pending
simple-workers-kszj2-d4c6b6f49-795l5: pending
simple-workers-kszj2-d4c6b6f49-m6sg9: pending
3. HAproxy.cfg populated with Frontend/Backend
haproxy.cfg got configured with frontend and backend settings:
frontend domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-kube-system-kube-apiserver-lb-svc
mode tcp
bind 172.16.97.193:443 name domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-kube-system-kube-apiserver-lb-svc-172.16.97.193:nginx
bind 172.16.97.193:6443 name domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-kube-system-kube-apiserver-lb-svc-172.16.97.193:kube-apiserver
log-tag domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-kube-system-kube-apiserver-lb-svc
option tcplog
use_backend domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-kube-system-kube-apiserver-lb-svc-nginx if { dst_port 443 }
use_backend domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-kube-system-kube-apiserver-lb-svc-kube-apiserver if { dst_port 6443 }
frontend domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-tanzu-ns-01-simple-control-plane-service
mode tcp
bind 172.16.97.194:6443 name domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-tanzu-ns-01-simple-control-plane-service-172.16.97.194:apiserver
log-tag domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-tanzu-ns-01-simple-control-plane-service
option tcplog
use_backend domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-tanzu-ns-01-simple-control-plane-service-apiserver if { dst_port 6443 }
backend domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-kube-system-kube-apiserver-lb-svc-kube-apiserver
mode tcp
balance roundrobin
option tcp-check
log-tag domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-kube-system-kube-apiserver-lb-svc-kube-apiserver
server domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-kube-system-kube-apiserver-lb-svc-172.16.96.10:6443 172.16.96.10:6443 check-ssl weight 100 verify none
server domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-kube-system-kube-apiserver-lb-svc-172.16.96.11:6443 172.16.96.11:6443 check-ssl weight 100 verify none
server domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-kube-system-kube-apiserver-lb-svc-172.16.96.12:6443 172.16.96.12:6443 check-ssl weight 100 verify none
backend domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-kube-system-kube-apiserver-lb-svc-nginx
mode tcp
balance roundrobin
option tcp-check
log-tag domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-kube-system-kube-apiserver-lb-svc-nginx
server domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-kube-system-kube-apiserver-lb-svc-172.16.96.10:443 172.16.96.10:443 check-ssl weight 100 verify none
server domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-kube-system-kube-apiserver-lb-svc-172.16.96.11:443 172.16.96.11:443 check-ssl weight 100 verify none
server domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-kube-system-kube-apiserver-lb-svc-172.16.96.12:443 172.16.96.12:443 check-ssl weight 100 verify none
backend domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-tanzu-ns-01-simple-control-plane-service-apiserver
mode tcp
balance roundrobin
option tcp-check
log-tag domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-tanzu-ns-01-simple-control-plane-service-apiserver
server domain-c213501:B5CBA8B0-DCC4-4C81-8407-92E70AE3B8B0-tanzu-ns-01-simple-control-plane-service-172.16.96.13:6443 172.16.96.13:6443 check-ssl weight 100 verify none
Hi Kastro, I have the exact same problem. ( with newest vcenter ).
Tried again a few times, I’m very sure that networking is working fine but can’t seem to deploy the guest cluster.
I get the same
11m Warning ReconcileFailure wcpcluster/tkc01 unexpected error while reconciling control plane endpoint for tkc01: failed to reconcile loadbalanced endpoint for WCPCluster nstom/tkc01: failed to get control plane endpoint for Cluster nstom/tkc01: VirtualMachineService LB does not yet have VIP assigned: VirtualMachineService LoadBalancer does not have any Ingresses
Hi
Did you manage to find a solution?
I build all from scratch, same problem. Will look with network team for FW issues, VLANs…
There is few of us with same problems now, as far as I track blogs etc…
A few things to try …
1. Simplify deployment by using a combined Workload and FrontEnd network to begin with.
2. Make sure there is no DHCP on the network
3. With the CIDR calculator, make sure that the range used for the Load Balancers does not overlap with the range used for the Workload IPs.
4. Plumb up 2 simple VMs – one on the Workload network, and one on the FrontEnd network – make sure they can ping one another from the different networks.
5. After deploying the HA-Proxy, make sure that Load Balancer/FrontEnd IP range is pingable. Using an IP scanner such as Angry IP Scanner is also useful here.
I’m not sure what else to suggest after this has been done.
Hi all,
I’m receiving:
Error configuring cluster NIC on master VM. This operation is part of API server configuration and will be retried.
I can see 3 SupervisorControlPlaneVM’s ,all 3 have a nic in the mgmt network but only one of them has received a NIC in the workload network.
This is my second try, the first time only one supervisor VM was started, the other 2 didn’t receive any nic’s.
I’m not using nsx
Problem is resolved, but I don’t know why. Tried again a fourth time but this time I used a small control plane instead of tiny and it worked :-).
on my deploy i’m not see cluster compatible , and on incomatble i have two issue
Failed to list all distributed switches in vCenter 32906730-598f-47b3-93cf-2136bf6ddd38.
Failed to communicate successfully with NSX managers.
but i have vds and not istalled nsx. where is the problem ?
Hi Castro,
I didn’t find a solution. I’m using a 2node vsan cluster in my lab. I guess this might be the problem.
Ah yes indeed. You will required a 3 node cluster for this to work.
Thank you Cormac, will a 3 node VSAN cluster do the trick? In the documentation I can see that for VSAN you need a 4 node cluster, but perhaps a 3 node cluster will work as well for a homelab?
Yeah, this was picked up on by William Lam: https://twitter.com/lamw/status/1328497146618777600?s=19