DSM 9.0.1 – New RBAC Features
![]() The most visible feature in Data Services Manager (DSM) 9.0.1 is the appearance of some additional new objects in the navigation menu on the left hand side of the DSM UI. These are Namespaces and Data Services Policy. Customers who have already looked at VCF Automation, particularly as it integrates with DSM, may have some familiarity with these. Their purpose in DSM 9.0.1 is to align with RBAC features that are already in VCF Automation, specifically around multi-tenancy controls. Through the use of Namespaces and Data Service Policies in DSM 9.0.1, a DSM admin can now control which DSM users can consume which vSphere resources (via infrastructure policies). A DSM admin can also control which data engines DSM users have access to, as well as the versions of those data engines. Lastly, a DSM admin can specify which backup locations a DSM user is allowed to send their backups to. In this post, I will show you step by step how these new RBAC features work in tandem to provide multi-tenancy controls in stand-alone DSM 9.0.1.
The most visible feature in Data Services Manager (DSM) 9.0.1 is the appearance of some additional new objects in the navigation menu on the left hand side of the DSM UI. These are Namespaces and Data Services Policy. Customers who have already looked at VCF Automation, particularly as it integrates with DSM, may have some familiarity with these. Their purpose in DSM 9.0.1 is to align with RBAC features that are already in VCF Automation, specifically around multi-tenancy controls. Through the use of Namespaces and Data Service Policies in DSM 9.0.1, a DSM admin can now control which DSM users can consume which vSphere resources (via infrastructure policies). A DSM admin can also control which data engines DSM users have access to, as well as the versions of those data engines. Lastly, a DSM admin can specify which backup locations a DSM user is allowed to send their backups to. In this post, I will show you step by step how these new RBAC features work in tandem to provide multi-tenancy controls in stand-alone DSM 9.0.1.
Scenario
This is a scenario based on DSM-Managed infrastructure policies, with internally managed Namespace and Data Service Policies created in DSM. There is no VCF Automation in this preview. Assume then that I have already been running data engines on behalf of certain groups in my organization, such as sales, marketing and finance. Now let’s assume that the engineering department has learnt what I can offer them through self-service, and all the other features we have with DSM such as automated lifecycle management, backups, fleet management, custom certificates, etc. So how can I give these guys from engineering their own sandbox to test out, for example, Postgres databases? First of all, I want to make sure that the engineering team have their own set of resources for deploying databases, and that they don’t start consuming any of the resources assigned to the other teams. I also want to make sure that they have their own backups location, and that they don’t have access to the backup locations used by the other teams. I also want to ensure that the engineering team are only testing a certain version of Postgres, as per my “line of business” compliance standards. Let me show you one approach to how this might be achieved with our new RBAC features built into DSM.
1. Create an Engineering Namespace on DSM
The first step, as a DSM admin, is to create a new Namespace object in DSM. This will be used to hold my engineering users. Simply give it a name a an optional label or labels for identification purposes. In this case, I have set a single label called “owner: george” to remind me who in the engineering team will be using the data service. But you can use labeling for any number of different purposes.
 Once the namespace is created, it should appear in the namespace listings. Note that all of these are “internally managed” namespaces. None of these are coming from VCF Automation integration.
Once the namespace is created, it should appear in the namespace listings. Note that all of these are “internally managed” namespaces. None of these are coming from VCF Automation integration.
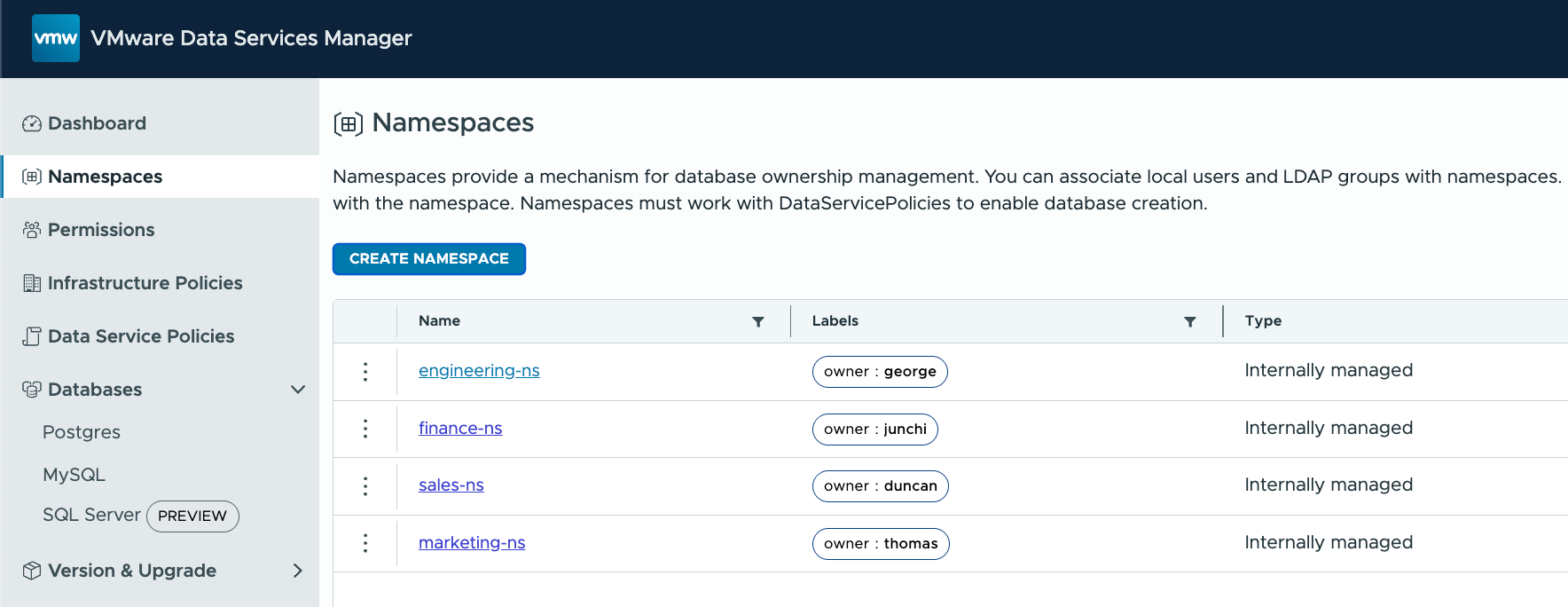
Note that, under the covers, any databases created by the users of these different namespaces will have their databases instantiated in a namespace of that name in the underlying Kubernetes cluster which runs my database. However, this is an implementation detail, and shouldn’t really matter to end users.
2. Add Engineering Group from Active Directory to DSM
Let’s now start bringing my engineering team into DSM. They are part of an Active Directory group called “engineering”. As a DSM admin, I have already configured my DSM Directory Services with this Active Directory integration. The group contains the engineering users that I wish to grant Postgres database creation capabilities.
Here is my AD group with my engineering users:

And here is my Directory Services configuration, mentioned previously:

I have already added a number of different AD Groups to my DSM environment to help me manage different users from Finance, Marketing and Sales:

My goal now is to import the ‘engineering’ AD group seen earlier. Simply click on the Import Directory Service Group, and you will be prompted for the name of the group as shown below. The users in the group can be configured as DSM admins or DSM users. If DSM users is selected, you will be prompted to add them to a Namespace. Namespaces are used to manage the users from different departments. Thus, I am only adding these AD users from the AD group ‘engineering’ to the “engineering-ns” Namespace.

3. Create a Postgres Data Service Policy for engineering
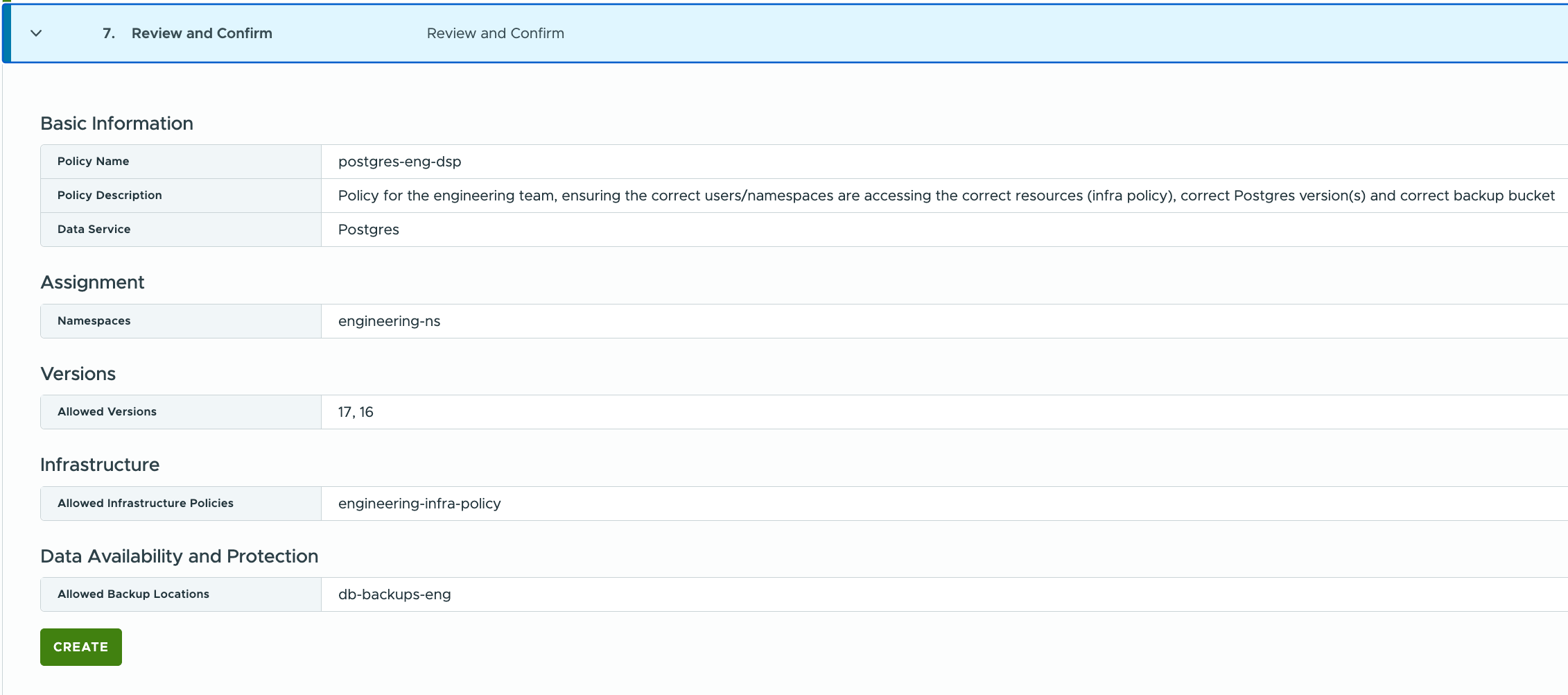
With the AD engineering group imported, and the users associated with the ‘engineering-ns’ namespace, I can now proceed with the creation of the Data Service Policy (DSP). The next objective is to grant these engineering users access to certain versions of the Postgres engine, and provide them with a dedicated backup location. Under Basic Information, provide the policy name, optional description and which data service the policy is associated with:
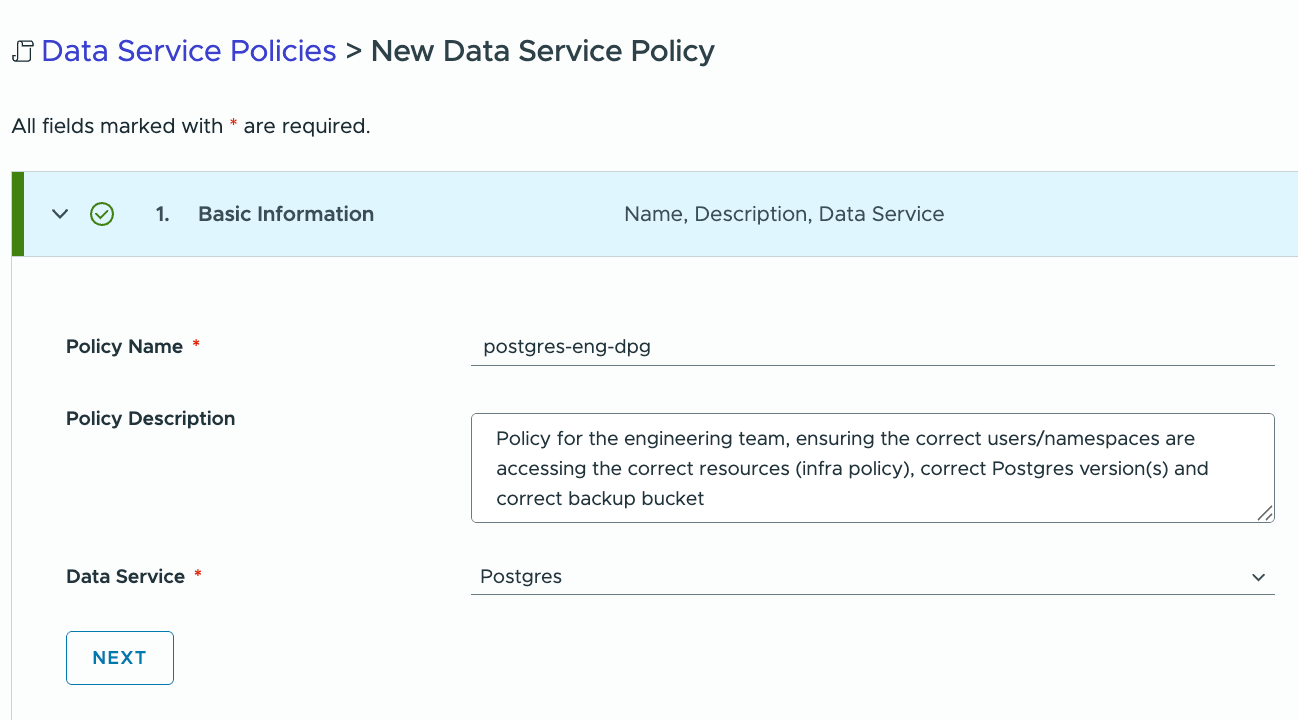
Click Next. The next step is to define the Namespace Scope. In other words, this is deciding which users can use this Data Service Policy. As I am focused on my engineering users, I am only going to select the ‘engineering-ns’ which means that any users who are in that namespace will be able to use this DSP. You could, of course, include additional namespaces in this DSP or create additional Postgres DSPs for other namespaces if you so wish.
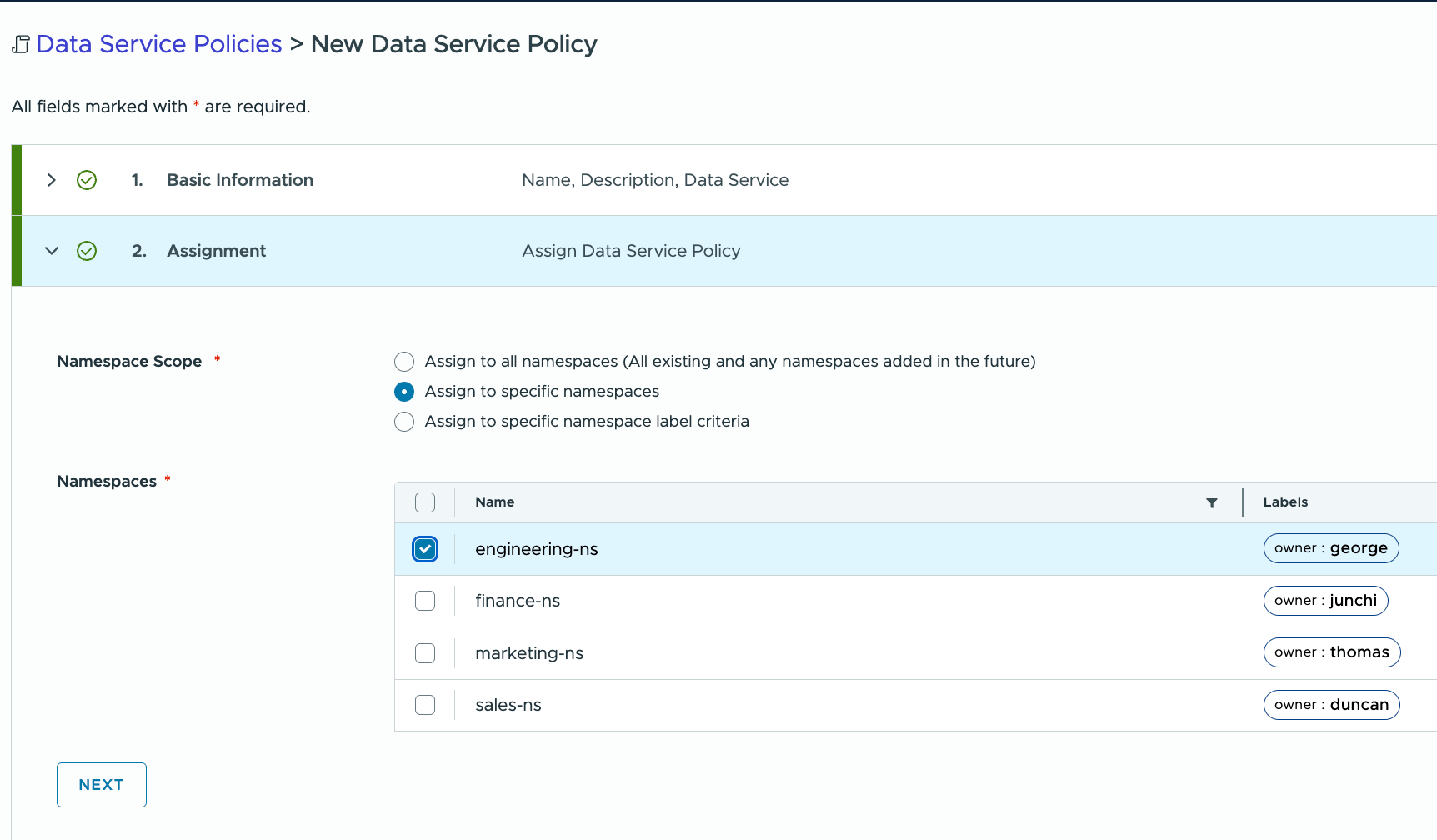
Next, select which version of the data service you wish to make available to the users of the DSP. Since I only enabled versions 16 & 17 on my DSM environment anyway, it makes sense to only allow only those versions to be selected.

Now we come to what, in my opinion, is possibly the most interesting part of the DSP. This is the selection of an infrastructure policy. This now enables DSM 9.0.1 admins to decide which users can use which parts of their vSphere infrastructure when deploying data services. For example, the engineering team may be assigned to their own VCF workload domain for test & dev. I can now build an infrastructure policy which contains resources from this workload domain only and, using a DSP, ensure that the engineering team can only provision their Postgres databases onto that part of my vSphere/VCF infrastructure. This means that whatever they deploy, they won’t be able to impact any of the other teams. Each team can be made to provision their data services onto their own separate infrastructure (compute, network, storage). Very neat indeed.

If desired, a backup location is now chosen as part of the Data Availability and Protection setting. Again, there is the ability to assign certain backup S3 compatible buckets to certain groups of users through the use of a DSP. DSPs allow admins to decide which buckets to assign to which users. This could be based on capacity, performance, retention, encryption and other factors, depending on the requirements of the user.
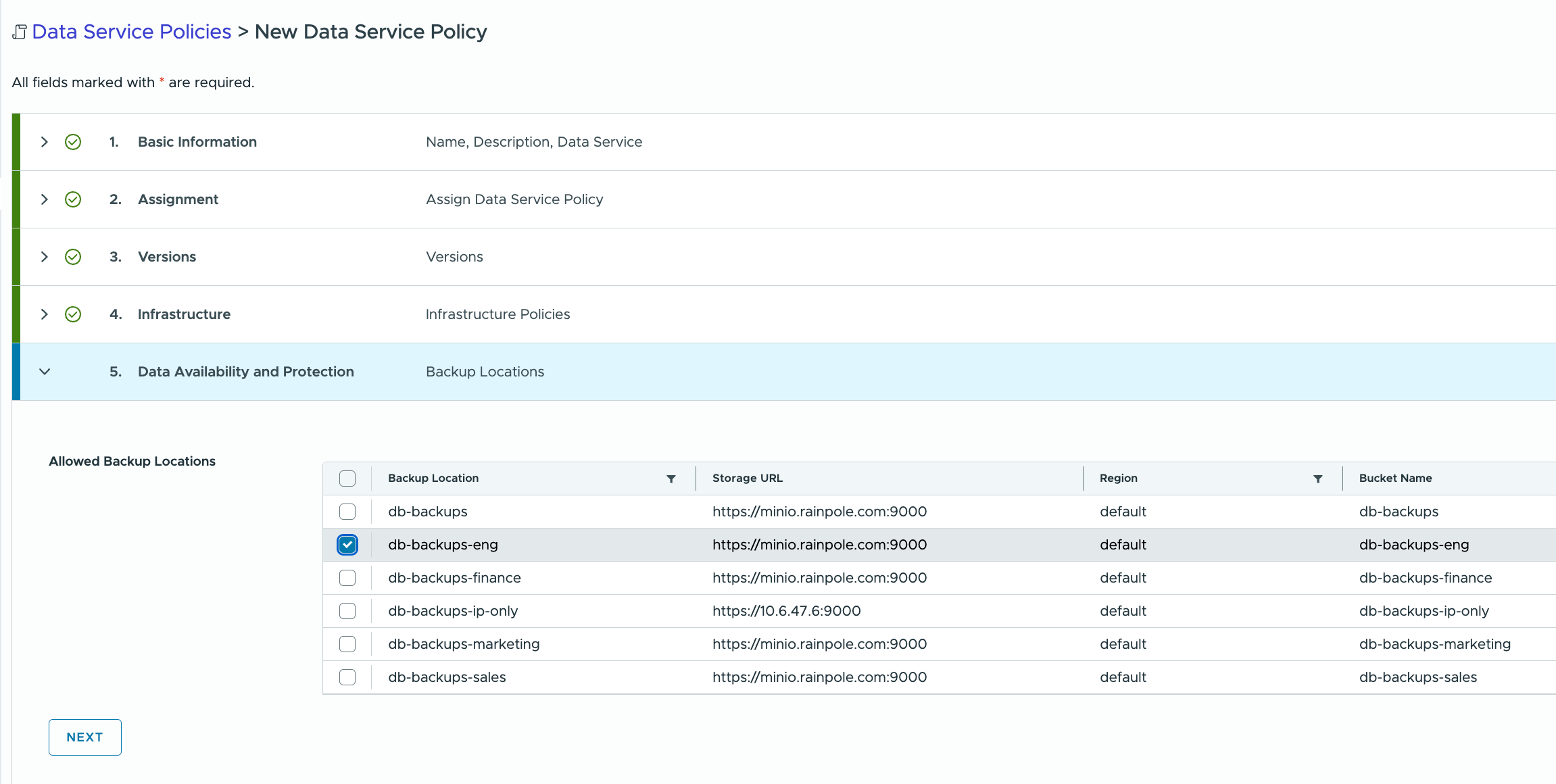
And now a compliance check is carried out to ensure that there are no Data Service Policy violations. This is checking to see if there are existing databases provisioned by namespace users which might not be met by the new policy, such as Postgres engine versions outside of what was selected in the policy. With newly created policies and namespaces, it is unlikely to cause violations unless there are multiple similar policies for the same namespace which are stepping on one another’s configuration.

Review your policy and create:
4. Check Data Service Policy behaviour
Let’s now go ahead and test the Data Service Policy. If everything is working, I should be able to create a Postgres database (version 16 or 17 only) as one of the members of the “engineering” group. However, this user should not be able to create MySQL or MS SQL Server databases. Let’s login as one of the engineering users and find out.

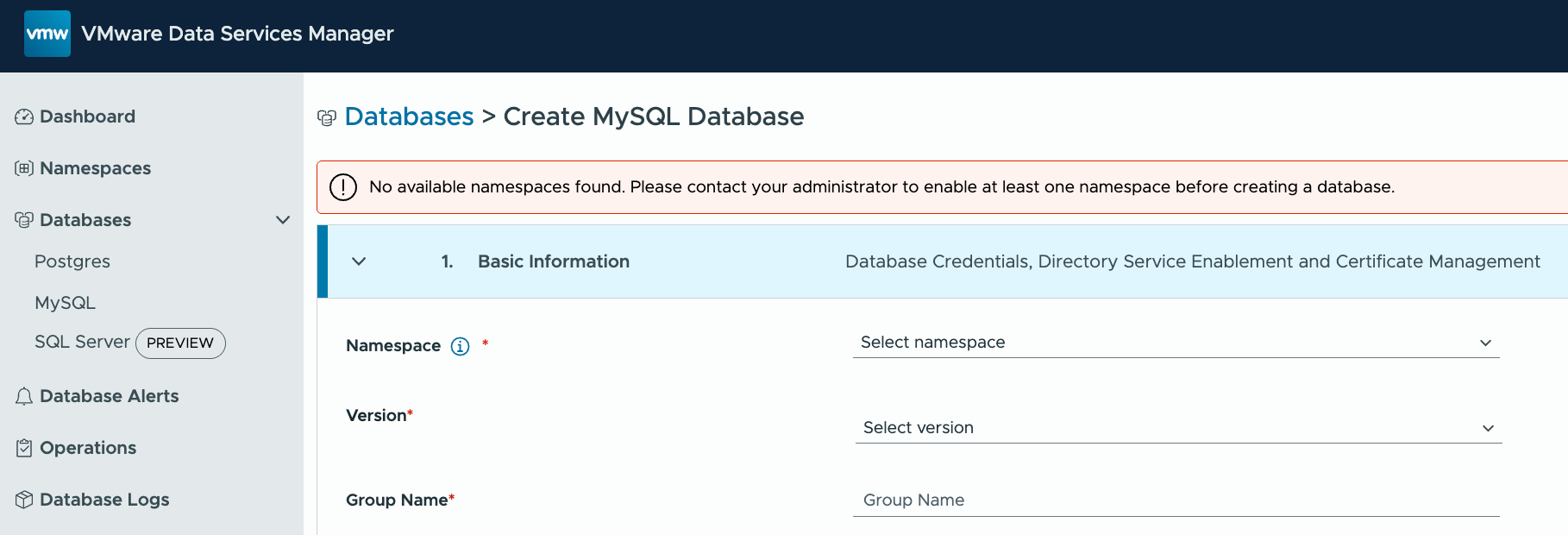
Now let’s try to create a Postgres database. This looks good. I only have access to the “engineering-ns” namespace, and I can only select Postgres versions 16 & 17 as per the policy.

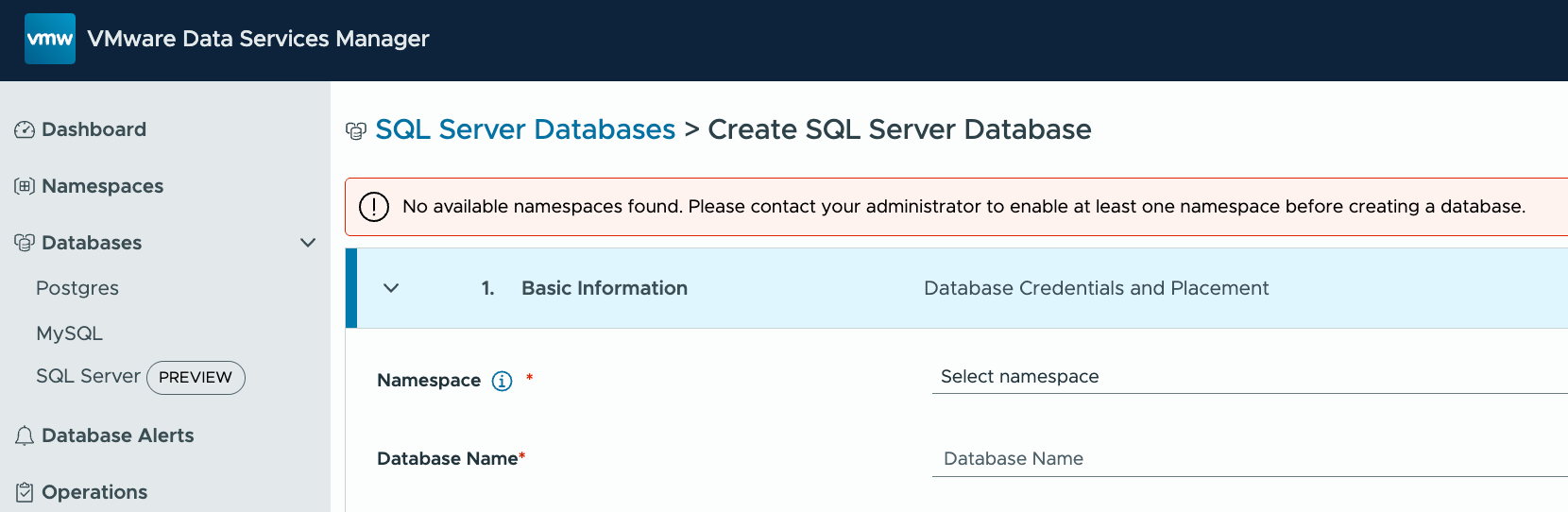
Now let’s see what happens when I try to create MySQL or MSSQL. As expected, neither the MySQL nor the MS SQL Server databases can be created as the engineering user only has access to Postgres. Attempts to create either a MySQL MS SQL Server database error out with “No available namespaces found”.
New VCF Automation Integration
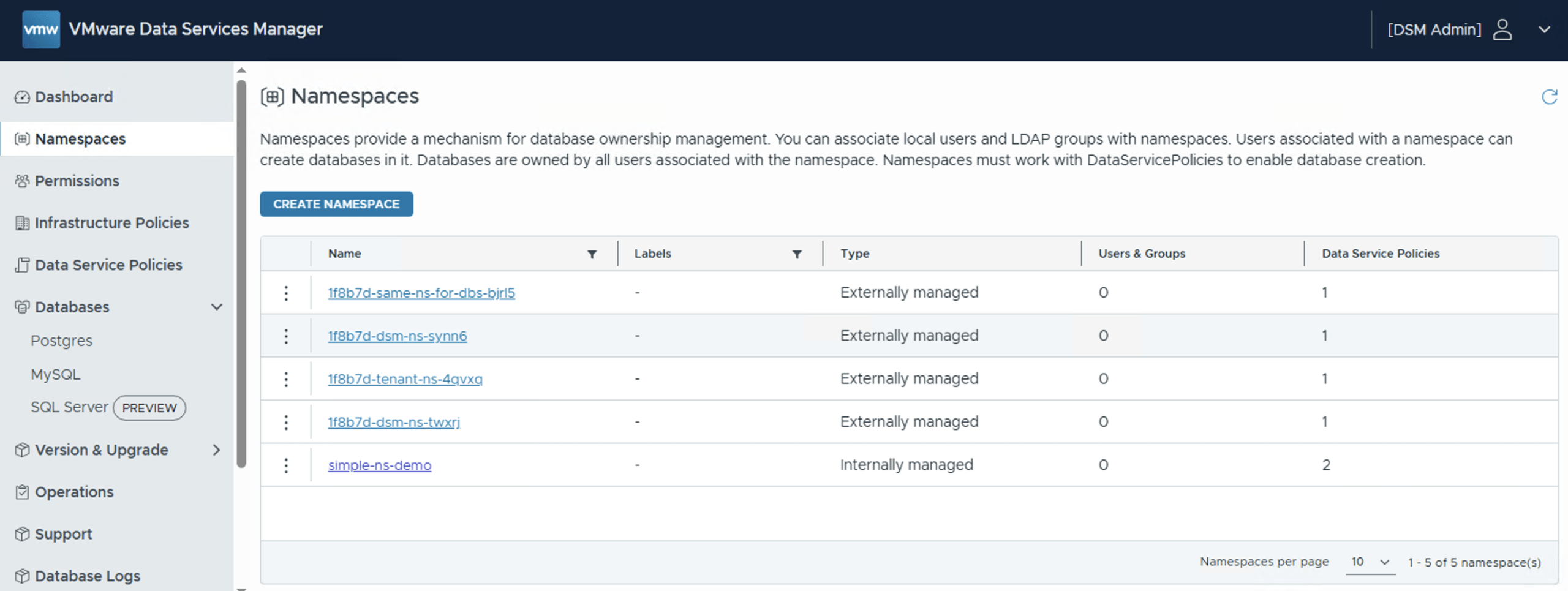
Before finishing this section, I did want to highlight the fact that the Data Service Policy and Namespace views in the DSM Appliance UI are also populated with appropriate information if DSM is integrated with VCF Automation. For example, if there are infrastructure policies created using Supervisor Namespaces rather than traditional vSphere resources, these also appear in the Namespace view in the DSM UI. Here is such an example. In the first screenshot below, the DSM created Namespaces (as described earlier in this post) are labelled as “Internally managed” whereas the Supervisor Namespaces (which can be used by VCFA to build infrastructure policies for databases) are labelled as “Externally managed”:
A similar view is available for Data Service Policies. Data Service Policies which are built via VCF Automation are also now visible in the DSM UI. DSPs create directly via the DSM UI are shown as “Created in” VMware Data Services Manager whereas those built via VCF Automation are shown as “Created in” VMware Cloud Foundation Automation.

Summary
That completes our overview of the new RBAC features in Data Services Manager version 9.0.1. As you can see, these are indeed quite powerful options, enabling administrators to have full control over which users can access which database engines and versions, which infrastructure policies and which backup locations. I’m sure you will agree that this is a very welcome enhancement to DSM.