A closer look at VMware Data Services Manager and Project Moneta
 As most of you know, last week VMware Explore 2022 was held in Barcelona for our European audiences. I must say, there was a great buzz around the Fira conference center. A lot of this was due to the gap since the last VMworld event in 2019, but I think that many of the announcements also generated a lot of interest. I have highlighted a number of these in recent blog posts, such as some of the new features in vSphere 8.0, vSAN 8.0 and TKG 2.0, as well as the launch of VMware Distributed Service Engine. However, one of the announcements that I wanted to learn more about was the tech preview of Project Moneta. In a nutshell, this is a project that is aimed at stopping data sprawl across an entire infrastructure, and give more governance and control back to the IT teams. To that end, I caught up with VMware Fellow (and my former boss) Christos Karamanolis to learn a bit more about it and VMware Data Services Manager.
As most of you know, last week VMware Explore 2022 was held in Barcelona for our European audiences. I must say, there was a great buzz around the Fira conference center. A lot of this was due to the gap since the last VMworld event in 2019, but I think that many of the announcements also generated a lot of interest. I have highlighted a number of these in recent blog posts, such as some of the new features in vSphere 8.0, vSAN 8.0 and TKG 2.0, as well as the launch of VMware Distributed Service Engine. However, one of the announcements that I wanted to learn more about was the tech preview of Project Moneta. In a nutshell, this is a project that is aimed at stopping data sprawl across an entire infrastructure, and give more governance and control back to the IT teams. To that end, I caught up with VMware Fellow (and my former boss) Christos Karamanolis to learn a bit more about it and VMware Data Services Manager.
Overview
In Christos’ VMware Explore session – VIB1487US – he shared the scenario of a company who were going through a digital transformation. He highlighted the difficulty with managing the data in such a transformation. When we talk about data here, we are not talking about blocks and files, but rather databases, messaging and streaming applications, K/V store, S3 object stores and so on. The company had many developers who were creating many new applications. These applications, in many cases, had a requirement on a database. However, it was the IT team who were responsible for the provisioning of these databases. Developers were expected to open tickets to get a new database provisioned by the IT team, and in many cases this took hours or even days to deploy. This was leading to a lot of angst amongst the developers. By the same token, the IT team were experiencing issues as well. There were many requests for different databases, different messaging and streaming products, and so on. IT was frantically trying to figure out how to manage, scale, backup, update and monitor this proliferation of data, while also making sure that each instance deployed adhered to the corporate security and compliance guidelines. Quite the headache!
And this is where VMware Data Services Manager (DSM) comes in. DSM offers developers a way to do self-service database provisioning, while IT continue to control resource consumption, ensure that the databases meet regulatory compliance, meet the necessary backup requirements and so on. DSM offers a single interface to both IT and developers, and offers a cloud-like experience for on-premises database deployments.
VMware Data Services Manager
Let’s talk a little bit about the controls that IT have over the databases that are being deployed. First and foremost, there is the concept of a namespace. This is simply a way of carving out vSphere resources to allow a developer to deploy a database but also controlling sprawl. IT creates the namespace. IT also creates a set of databases that are qualified by the business and are made available to the developers to consume. This avoids any poorly patched or non compliant databases from being used. Developers can only provision databases that have been blessed by the IT team. At present, VMware has validated three of the most popular databases for use with DSM. These databases are MySQL, PostgreSQL and SQL Server.
DSM eliminates the ticketing requirement, providing a cloud like experience for developers whilst continuing to keep resource control in the hands of the IT team. Once the developer logs into DSM, they can see an overview of the number and types of databases provisioned, how much capacity is available, and details about backups, as shown below.

Under the Databases section, developers can deploy new databases, but only with the versions and type that have been allocated by the IT team. In the example shown here, the developer is deploying a SQL Server database, using a version provided by the IT team, and is deploying it to a Namespace to which the developer has access. The developer does have the ability to fine tune the sizes of the virtual machines that are provisioned, but can never consume more resources than what has been allocated to the Namespace. And the developer can only provision a database from a database template which the IT team has “published”.

Further down in the workflow, the developer can add configuration parameters such as username and password, as well as define a backup and maintenance schedule for the database. All these schedules can be modified after the deployment if necessary.

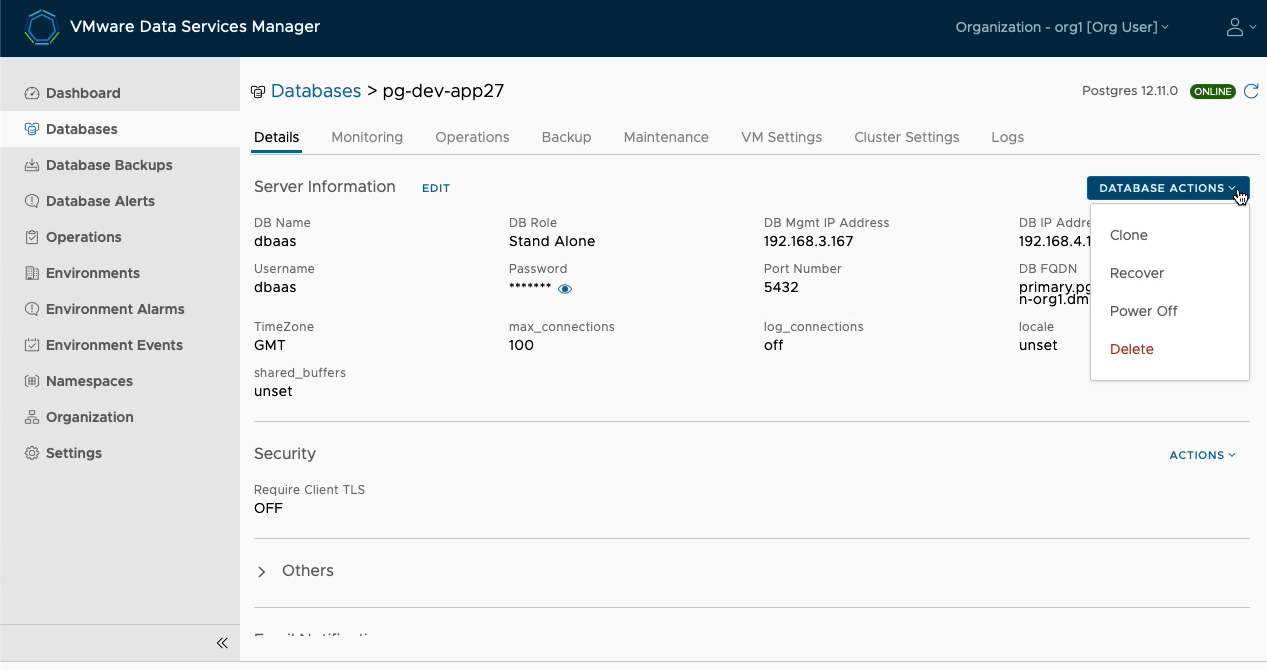
Developers can use the same portal for various day-2 self-service operations on the database. Developers can do operations such as clone the database, shut it down, change the owner, delete it, or even recover from a point-in-time (PIT) copy This is all driven through the DSM UI to which developers have access. Most importantly, there is no need for the developers to contact IT via a ticketing system for these operations. Below are some of the actions available to the developer, including the ability to recover a particular database backup.
From an IT perspective, DSM provides the IT team with a centralized console to monitor all database deployments across their infrastructure. This centralized console provides infrastructure specific metrics ranging from health to performance to top resource consumers. Below is a view of DSM Health showing everything is OK.

Host Metrics displays ESXi host information such as network usage, as well as CPU and Memory usage. Database Metrics provides insights into the top 10 CPU and Memory consumed databases, as well as per database CPU And Memory usage over a particular period, e.g. the past 12 Hours. Storage Metrics allow the vSphere datastore to be examined from a read and write average perspective, again over a period of time. The DSM console also allows logs to be captured from the various databases and exported to an external logging system. From an update perspective, IT can automatically schedule minor updates to be applied to databases, but only during a maintenance window which can also be configured to mitigate impact to the developers.
And last but not least, DSM also has a full REST API should developers wish to automated the deployment of these databases.
The point to take away from VMware Data Services Manager is that it gives the developer the flexibility to provision databases through self-service without the need to raise a ticket with IT, while providing the IT team with the controls to ensure that any databases deployed in their environment meet their security and compliance guidelines, whether this is control over database types, database version control, backup scheduling, maintenance windows, etc. I am sure you will agree that this is pretty compelling. Let’s now take a look at what the future might hold.
Introducing Project Moneta
When discussing VMware Data Services Manager in the previous section, we were purely focused on an on-premises solution. However, many of our customers have multiple vSphere environments to manage, often geographically dispersed. vSphere+ is providing a centralized software as a service (SaaS) management portal for all of these different vSphere infrastructures. The plan for Project Moneta is to tightly integrate with both vSphere+ and the Cloud Consumption Interface (CCI). You can read more about the Cloud Consumption interface in William Lam’s excellent blog here. In a nutshell, the objective will be to provide a universal interface for both developers and IT to access all of their vSphere infrastructure and all of their underlying databases across cloud, on-premises, at the edge, and so on. The longer term goal of Project Moneta is to extend the Cloud Services in vSphere+ to also offer databases as a service (DBaaS). This should also extend to out VMware Cloud Provider partners to also offer DBaaS in their own sovereign clouds. Below is a screenshot of what the launchpad for Project Moneta “might” look like in the future. However, it is very early days still, so much of what is shown in the UI workflow below will probably change.

What is particularly nice about Project Moneta is that we plan to have it integrate with GitHub / GitLab. Each database that is provisioned through the CCI console will generate its own sample YAML manifest. This will be automatically stored on the developers GitHub or GitLab account. These manifest can then be ‘watched’ for changes or updates, and can be incorporated into a developer’s own CI/CD pipeline. If a tweak needs to be made to the database from, for example, a resource perspective, the pipeline can be triggered to automatically initiate a new rollout of the database. This is one of the major differences between VMware Data Services Manager and Project Moneta. DSM deploys database as a set of virtual machines, whereas Project Moneta will be able to deploy databases as either VMs or Containers, depending on the type of database that is being provisioned. Through the CCI console, a full view of the YAML manifest used to create the database can be observed as shown below.

And here is the deployment of the database which can be observed via the CI/CD pipeline job. We can see that the job succeeded right at the end, but all of the kubectl and other commands to create and configure both the Kubernetes cluster and the database application can be observed by scrolling back through the job steps.

To conclude, Christos shared our vision for Project Moneta. The goal is to provide platform that is open to the ecosystem. In other words, we want to support any database, including open source databases. This is certainly a very exciting prospect, and something I hope to provide regular updates on over the coming year. For further information, check out the VMware Explore session highlighted at the beginning of this post. There is also an excellent interview with Christos on DSM & Project Moneta in the Unexplored Territory podcast, episode #028. Check it out!
Sounds like a lot of overlap with RDS on VMware ?
https://aws.amazon.com/about-aws/whats-new/2019/10/amazon-rds-on-vmware-is-now-generally-available/
RDS on VMware seems to be discontinued since that 2019 post
Yep. Not seen anything about this in a long time, nor have I spoken to any customers who are using it.
True. I believe the objectives are somewhat the same. Give IT the control to manage resources, adhere to corporate compliance and security guidelines, while at the same time giving developers freedom of choice and self-service. I think this is one of the more interesting products we’ve created in recent times. I plan to do a few follow up blogs on how to get started with it.
Indeed, seems like the idea of a “VMware Customer Availability Zone” vanished…