
This is the third blog post in a series which describe how to get started with VMware Data Services Manager (DSM), a VMware solution that offers on-demand provisioning and automated management of databases on vSphere environments. In a previous installment, the deployment and configuration of the Provider appliance was discussed. In a follow up post, the steps to provision and configure an Agent were described. In this final installment related to the deployment of DSM, the addition of users is covered. So far the only user we have been dealing with is the Provider Admin. In this post, we will create a new Organization Admin user followed by a Namespace to identify vSphere resources. The Org Admin can then provision databases. They can also give ownership of a database to an Org User, most likely a developer. The post will then proceed to create a Namespace construct in DSM to allocate vSphere resources for the database before finally deploying a PostgreSQL database.
Create an Org Admin User
To create a new user, simply select Users from the left-hand navigation pane in the DSM UI, and click on the ‘Create User’ button. Note that there is the option to select between a User and an Admin. In this example, I have made user Frank and Org Admin. The organization that I chose, rainpole-devs, is a tenant organization, not the provider organization. This tenant org was created when we deployed the Provider in an earlier post.

With the Org Admin successfully created, we can now proceed with the creation of a Namespace.
Namespace Creation
In VMware Data Services Manager, a Namespace can be considered as a group of resources that consists of datastores, networks (application network), and external storage (local and cloud storage). It is a construct that is created by a Provider Administrator to group resources that are used for provisioning a database. Since there is a requirement to include external storage in the namespace, some additional setup needs to be done to specify database backup S3 buckets before the Namespace can be created. To do this, navigate to the Settings option in the left-hand navigation window in the Provider UI. Select Storage Settings to see the Database Backup Storage section. Currently, there is no database backup storage defined, as shown below.

Click on the + Create link to add some database backup storage. These database backup storage entries refer to existing S3 Object Store buckets. One is created for local backups and another is created for remote/cloud backups.

Once the database backup storage is defined, we can proceed with the Namespace creation. Select Namespaces from the left-hand navigation pane, and then click on the ‘Create Namespace‘ button. The first step is to provide a name and optional description for the Namespace. I called it devs-ns.

Step 2 is to select an environment. This is a vSphere Cluster which has an Agent deployed. This Agent deployment is the activity which was carried out in the second blog post in this series. The selected environment (vCenter, Datacenter, vSphere Cluster) is where the database VMs will be provisioned.

Now you need to select the database backup storages, which is what was setup immediately prior to creating the Namespace. As you can see, it is looking from a local S3 bucket and a cloud S3 bucket. Both are required. However, since I did not have access to a cloud-based S3 provider, I simply created two buckets on the same on-prem MinIO server. This is OK as a proof of concept, but for production environments, please note the directive below which says not to use the same S3 storage for the local and cloud storage.

The next step is to choose a datastore on which the database VMs will be provisioned. Since my vSphere cluster has been configured with vSAN, I chose the vSAN datastore.

The penultimate step is to choose an application network. This is the network on which the clients will access the database after it has been deployed. Note that this network must have a DHCP server, as this is how the VMs gets IP addresses assigned to their interfaces. DNS must also be available on this network. Note that the VMs provisioned for databases are also plumbed up onto the control plane network. The control plane network must also have a DHCP server so that the control plane network interface(s) get allocated IP addresses.

Finally, you must choose which organization to assign the Namespace to. In this setup, I only have two organizations. The first is the Provider organization which is created automatically when the Provider is deployed. The second is a Tenant organization which I made during the configuration of the Provider. In this case, I am going to select the Tenant organization called rainpole-devs to associate with this Namespace, and this Tenant organization has fdenneman@rainpole.com as the Org Admin.

The new Namespace has now been successfully created.

Create a database as an Org Admin
It is now time to switch user contexts. I logout of the DSM UI as the Provider Admin, and log back in as the Org Admin, Frank. As the Org Admin, I will create a database using the recently devs-ns namespace resources created in the previous step. After logging in to the DSM UI, I am presented with the following Org Admin dashboard.

From here, I select the Databases entry on the left-hand navigation pane. Currently there are no databases created, so I simply select ‘Create Database‘. This launches a wizard which guides me through the creation of a database. Note that the only database I can select at present is PostgreSQL version 12.12 as this is the only one which the Provider Admin has published during the deployment of the Provider. This means that IT (vSphere Admin) still controls which databases can be deployed on the vSphere infrastructure. The Provider Admin could of course publish other databases and other versions if they so wish, allowing the Org Admins to create other database types and versions, but the idea here is to demonstrate how IT is still able to control database deployments and versions.
After selecting the database and version, a VM name is automatically created. This can be changed by the Org Admin. Also note that the FQDN for the VM and database uses the suffix that was associated with the Tenant Org when it was created. Ensure that the DB FQDN Suffix is set correctly in the tenant org before deployment. The next setting to select is the Namespace. At present, this Org Admin only has access to one Namespace, devs-ns1, so that is the only one which can be chosen. Optionally, tags can be added to the database to assist with searching later on. This could be useful if many databases are being deployed. The Org Admin now decides if they want to select a VM from a VM Plan (also covered in the deployment of the Provider blog post) or alternatively, choose to deploy the database using a VM with a a default resource configuration.

Additional configuration options are available to fine tune items such as database backup schedule, maintenance windows and even advanced database settings. Once the configuration has been completed, the summary displays all of the database deployment information.
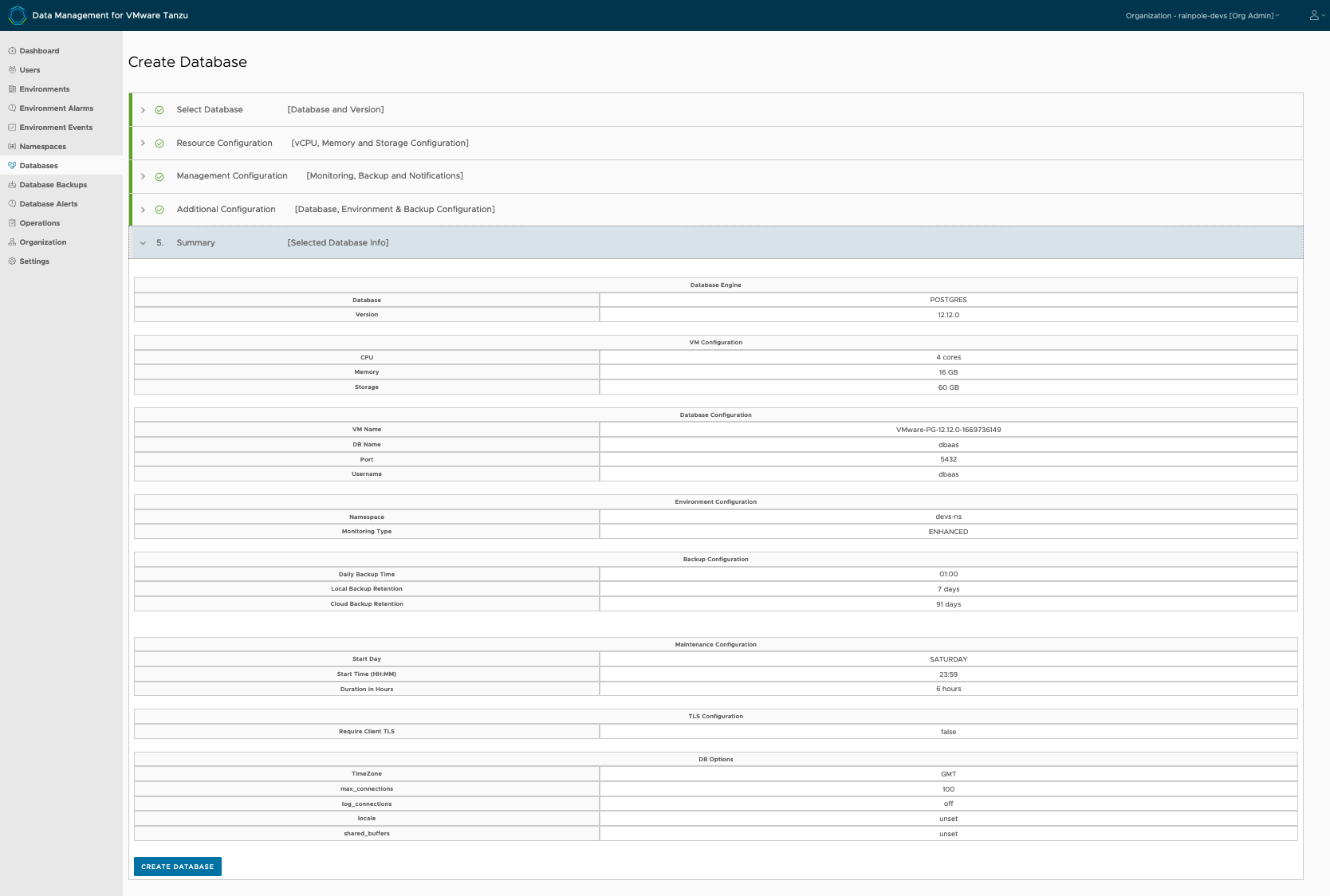
Assuming everything is correct, the Org Admin clicks on the ‘Create Database‘ button. This will trigger a download of the PostgreSQL database template(s) from the provider storage to the agent storage, and will then initiate the deployment of the VM with the appropriate resources. The additional database components are then added and subsequently configured, giving you a completed database deployment on the vSphere infrastructure (vCenter, Datacenter, Cluster, datastore, network). If everything works as expected, the database VM should startup and get IP addresses assigned on both the control plane network interface and the application network interface. As mentioned, both IP address should be provided by DHCP. On examining the databases view in the UI, the Org Admin should see something similar to the following.

By clicking on the name of the database in the above view, further details can be gathered about the database. The details page reveals details about the database, such as network addresses, username and password, and other details.

The DSM UI has other nice features, such as a monitoring view of the database. This provides an overall health view of the database, and will highlight if any of the components are in error. This will make troubleshooting database issues much easier.

There is also a backup and maintenance view, which means that the Org Admin can change the schedules and windows from the default ones which were allocated at database provisioning time. In the backup view, a list of local (L) and cloud (C) backup is shown. The first backup is full, whilst all subsequent backups are incremental. The Actions menu provides options to do restores. There is also an option to take a backup now of the database, should there be a need to do so.

Finally, the VM resources can be viewed under VM Settings. The Actions menu here allows the Org Admin to modify the compute resources, and also to extend the disk used by the database, should that be necessary.

That now concludes the series of blog posts on deploying VMware Data Services Manager. We have seen how to deploy the Provider, and use the DSM UI to complete the configuration. We also saw how to deploy an Agent onto some vSphere Infrastructure where we wish to deploy databases. And finally in this post, we saw how to create a Namespace construct which guard-rails which resources can be used for deploying databases on vSphere infrastructure. At this point, it should also be possible to understand that certain control remains with IT / vSphere Admins, e.g. database types and versions, backup schedules, maintenance windows, etc., whilst still providing self-service provisioning of databases to the developer community in your organization.
I hope this is post useful. Thanks for reading this far. For a full process on how to deploy DSM, you can find the Provider deployment details here and the Agent deployment details here. Please reach out if you have any comments or suggestions. Is VMware Data Services Manager something you would find useful in your environment? What enhancements do you think we could make to the product to reduce the friction even more between IT teams and developer teams? I look forward to hearing from you.